
目次
機械学習で必要不可欠!
「データセット」について
前回、機械学習を行う環境を準備しました。
今回からは、機械学習をするために必要なたくさんのデータ「データセット」について確認します!
データセットには、植物の品種のデータセットや人の顔を集めたデータセット、さらに応用として架空のデータも作成出来ます!
今回はscikit-learnのサンプルデータセットを見てみましょう!
scikit-learnのサンプルデータセット
scikit-kearnは、機械学習をやさしく学べるライブラリです。
機械学習のサンプルデータやアルゴリズムが色々入っており、さらに架空のサンプルデータを作り出すことも可能です!
どんなデータセットがあるか見てみましょう!
| 内容 | ロード命令 |
|---|---|
| ボストンの住宅価値 | load_boston() |
| アヤメの品種 | load_iris() |
| 糖尿病の進行状況 | load_diabetes() |
| 手書きの数字データ | load_digits() |
| 運動能力データ | load_linnerud() |
| ワインの種類 | load_wine() |
| 乳がんの診断結果 | load_breast_cancer() |
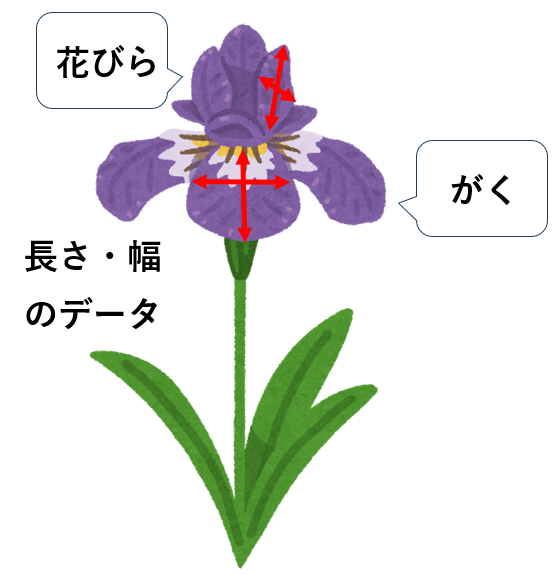
アヤメの品種データセット
では、実際に「アヤメの品種」のデータセットを見てみましょう。
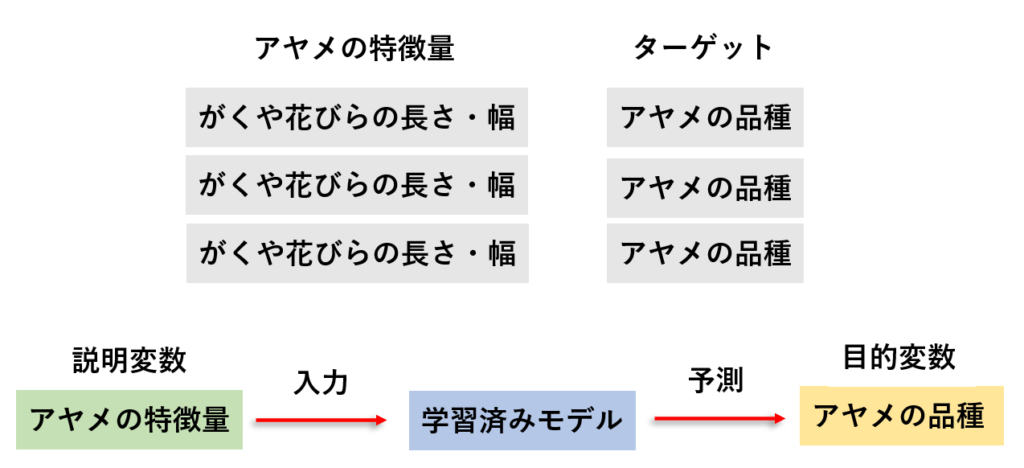
ここには「アヤメの様々な特徴量」や「どのアヤメの品種なのか」といったデータが入っています。
この「がくや花びらの長さ・幅などのアヤメの特徴量(説明変数)」を使って「アヤメの品種(目的変数)」を予測するという流れで、機械学習に使うことができます!
参考資料:Python3年生機械学習のしくみ
ここまでがデータセットの説明です。
では、これらデータセットを使って実際に機械学習に触れてみましょう!