
目次
アヤメのデータセットを確認方法
前回、アヤメのデータセットについて学習しました。
今回は、アヤメのデータセットの中身を確認します!
まず最初に新規ノートブックを作成してスタートです!

①データセットを読み込んでそのまま表示しよう!
sklearn(Pythonで読むこむ際に使うscikit-learnライブラリの名前)の中からdatasetsを取り出します。
コード
#1 ライブラリをインポート
#2 irisデータ(アヤメのデータ)を読み込む
#3 読み込んだデータをそのまま表示
from sklearn import datasets #1
irisdata = datasets.load_iris() #2
print(irisdata) #3参考資料:Python3年生機械学習のしくみ
実行結果

たくさん数字が出ましたが、これらはデータセット中に何種類ものデータが入っていることを表しています。
下の表はアヤメのデータセットの中に入っている内容です。
| データ名 | 内容 |
|---|---|
| data | 学習用のデータ |
| feature_names | 特徴量の名前 |
| target | 目的の値(分類の値) |
| target_names | 目的の名前(分類の名前) |
| DESCR | このデータセットの説明 |
②特徴量や分類の名前を確認しよう!
アヤメのデータセットに、『どんな種類のアヤメの特徴量データ』が入っていて、『どのような分類になっているのか』を見てみましょう!
コード
#1 特徴量の名前:feature_names
#2 分類の名前:target_names
#3 各データの分類:target
print("特徴量の名前 = ", irisdata.feature_names) #1
print("分類の名前 = " , irisdata.target_names) #2
print("分類の値 = " , irisdata.target) #3参考資料:Python3年生機械学習のしくみ
実行結果
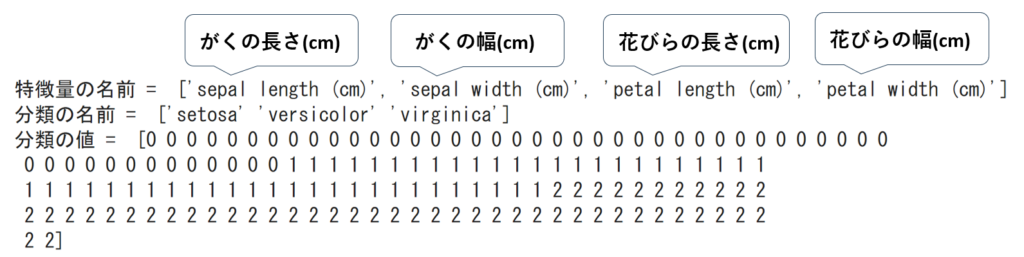
分類の名前に3種類の名前がありますがそれぞれ以下の特徴があります。
| 英語名 | 和名 | 特徴 |
|---|---|---|
| setosa | ヒオウギアヤメ | 北海道・アラスカなどに分布 |
| versicolor | バージカラ― | アメリカ東部・カナダ東部などに分布 |
| virginica | バージニカ | アメリカ南東部に分布 |
分類の値の番号は
0:setosa
1:versicolor
2:virginica
に対応しています。
これでデータを読み込んで中身を確認することができました!
次は、データフレームを作成していきましょう!