
目次
③データをデータフレームに入れよう
読み込んだデータを、処理しやすいようにデータフレームにいれます。
データフレームとは2次元のデータ構造で行と列で表現されます。
データフレームでは、列には列名、行には行名(インデックス)がつけられており、名前を指定してデータを処理することが可能です。
コード
#1 pandasをインポート
#2 irisdata.dataをデータフレームにする
#3 先頭5行を表示
import pandas as pd #1
df = pd.DataFrame(irisdata.data) #2
df.head() #3参考資料:Python3年生機械学習のしくみ
実行結果
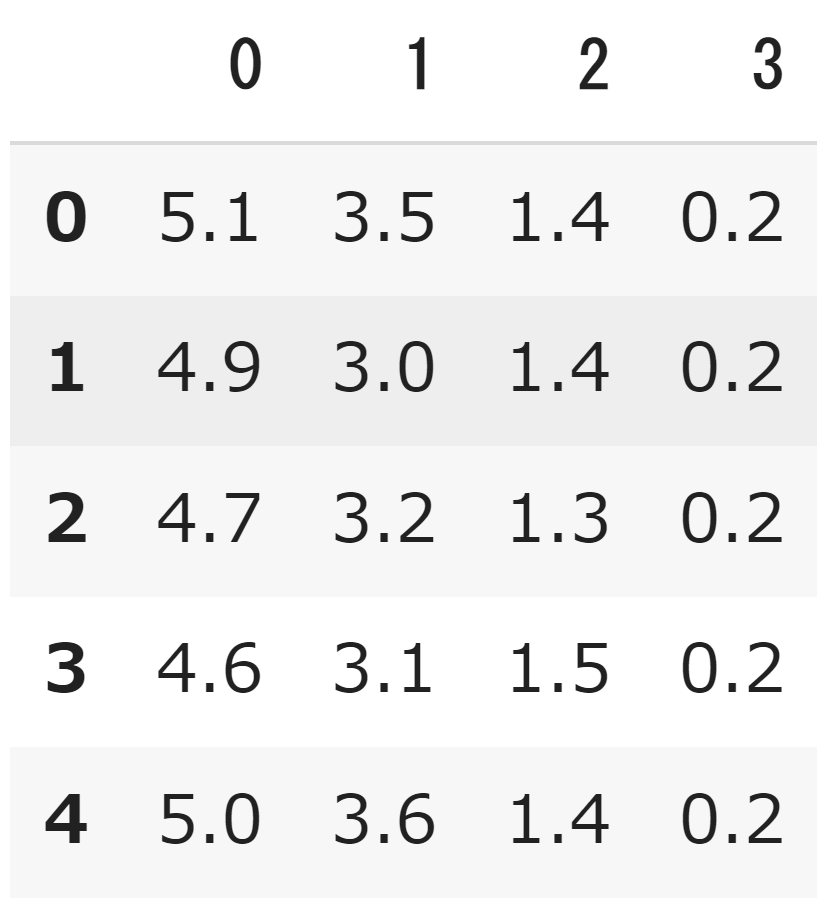
この表の意味は以下の通りです。
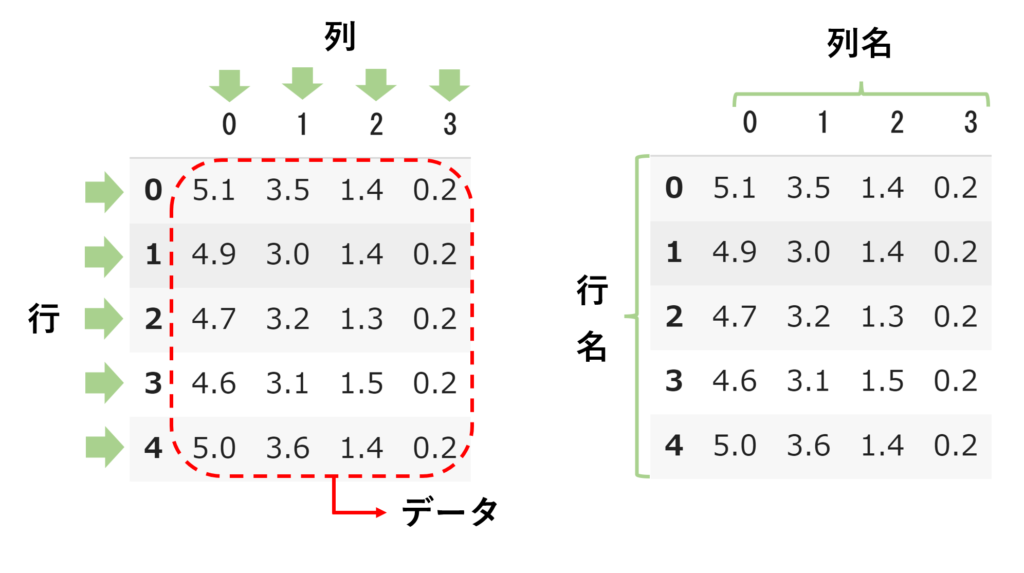
④列名に特徴量を設定し、どんな品種なのか追加しよう
先程の実行結果の通り、列名が数値になっていて意味が分かりづらいので列名を特徴量に置き換えます。
また、どんな品種なのかをtargetとして追加しましょう!
コード
#1 列名を特徴量に設定
#2 targetを列に追加
#3 先頭5行を表示
df.columns = irisdata.feature_names #1
df["target"] = irisdata.target #2
df.head() #3参考資料:Python3年生機械学習のしくみ
実行結果
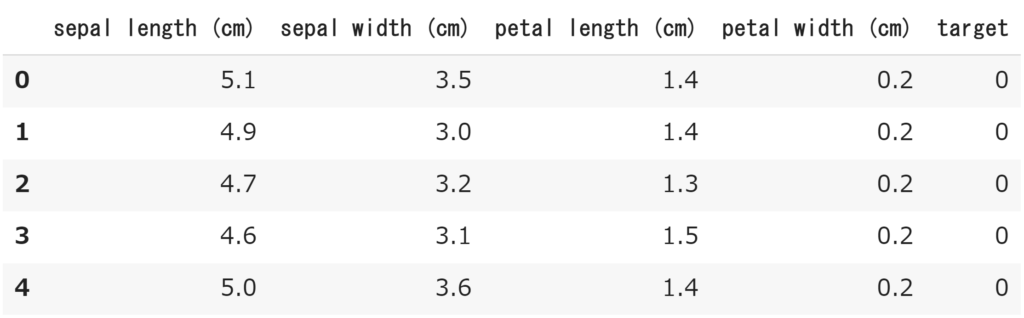
先程の結果に比べると分かりやすくなりましたね!
また、targetの列が増え、すべて0(setosa)が表示されています。
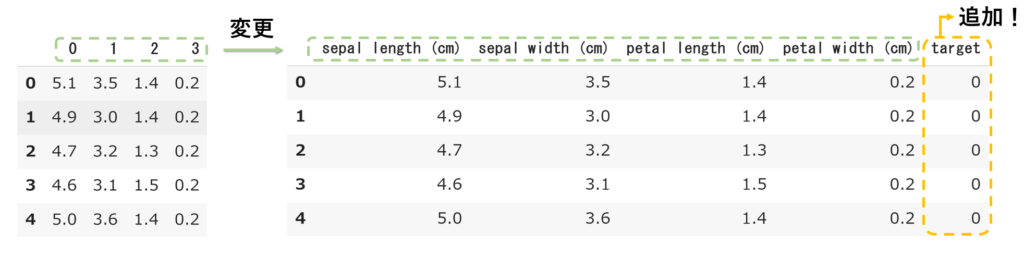
列名を変更して少し分かりやすくなりましたが数字のみで全体が理解できません。
なので、より理解しやすいようヒストグラムにしてみましょう!
⑤ヒストグラムで表示しよう
アヤメのがくの幅のデータをヒストグラムにしてみましょう。
品種が3種類あるのでそれぞれを違う色で描画して違いを確認しましょう!
ここで、変数[xx]にsepal width(cm)という列名を入れ、df0[xx]、df1[xx]、df2[xx]、で指定して描画します。
コード
#1 targetが0のときdf0
#2 targetが1のときdf1
#3 targetが2のときdf2
#4 5×5のグラフを作成
#5 sepal width(cm)(がくの幅)列を対象にする
#6 シアンのヒストグラムを作成
#7 マゼンタのヒストグラムを作成
#8 黄色のヒストグラムを作成
#6~8 半透明(alpha=0.4)に設定し、重なってもわかるように
#9 ラベルをグラフのx軸に設定
import matplotlib.pyplot as plt
# 品種3種類を別々のデータフレームに分ける
df0 = df[df["target"]==0] #1
df1 = df[df["target"]==1] #2
df2 = df[df["target"]==2] #3
# 品種3種類を色分けしてヒストグラムで描画
plt.figure(figsize=(5, 5)) #4
xx = "sepal width (cm)" #5
df0[xx].hist(color="c",alpha=0.4) #6
df1[xx].hist(color="m",alpha=0.4) #7
df2[xx].hist(color="y",alpha=0.4) #8
plt.xlabel(xx) #9
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
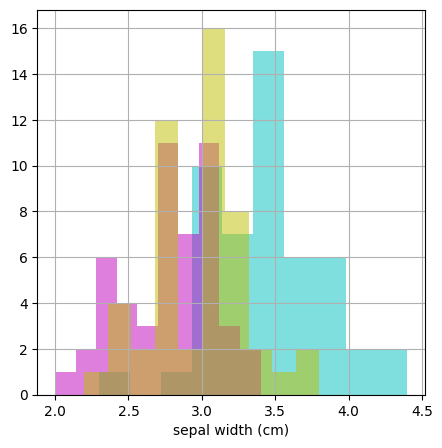
グラフを見るとそれぞれの山の位置が少しずつずれていることがわかります。
このことから、がくの幅に注目すると品種の違いがわかりそうだということが考えられますね!
しかし、まだはっきりと区別することが難しいので特徴量を2つに増やしてみましょう!