
前回でデータの準備ができたので、ここで少し「学習・予測方法」を整理してみましょう。
目次
学習・予測方法
学習方法
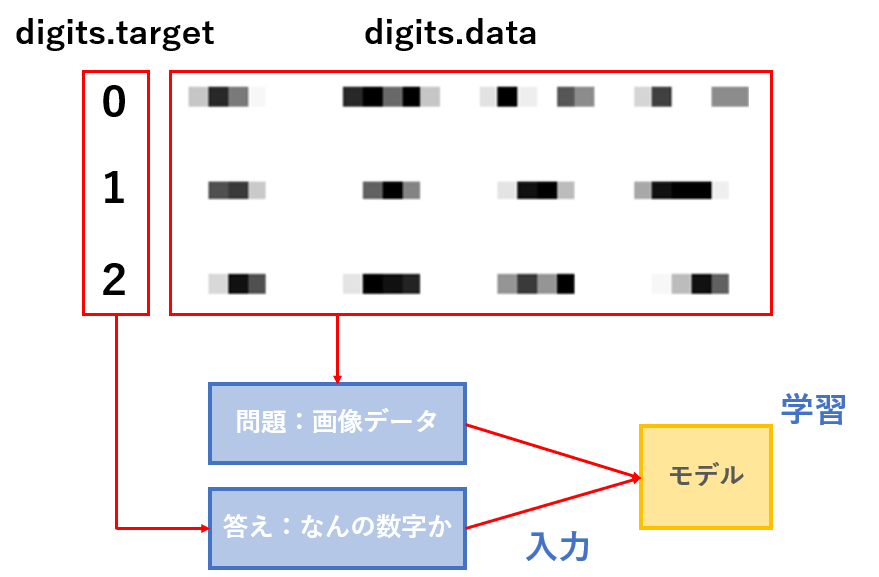
digits.data:数字の画像データ
digits.target:なんの数字か
問題としてdigits.dataを渡し、答えとしてdigits.targetを渡すことで学習できます。
予測方法
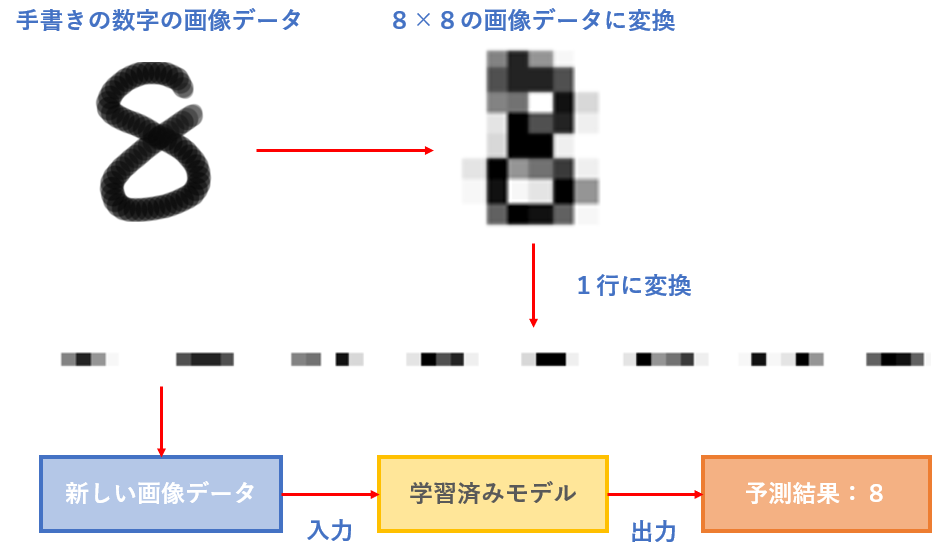
手書きの画像データを、8×8のモザイク画像に変換して、さらに1行(64×1)のデータに変換する処理が必要です!
データを学習用とテスト用に分ける
上で紹介した仕組みでデータを学習用とテスト用に分割して、個数を確認してみましょう。
コード
from sklearn.model_selection import train_test_split
X = digits.data
y = digits.target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) # データを分割する
print("学習用 =", len(X_train))
print("テスト用 =", len(X_test))参考資料:Python3年生機械学習のしくみ
実行結果
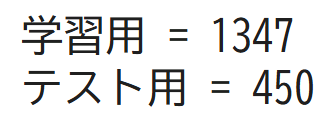
全体のデータの個数が1797個でしたので、75%分の1347個、25%分の450個に分けられていることが分かりました!
モデルを選んで学習させる
モデルはSVMを使います。また、非線形分類のkernel=”rbr”を指定して、境界線の複雑さはgamma=0.001としてしてみましょう。
コード
#1 訓練データでガウスカーネル法のSVMで学習モデルを作成
#2 テストデータで正解率を調べる
from sklearn import svm
from sklearn.metrics import accuracy_score
model = svm.SVC(kernel="rbf", gamma=0.001) #1
model.fit(X_train, y_train)
pred = model.predict(X_test) #2
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")参考資料:Python3年生機械学習のしくみ
実行結果
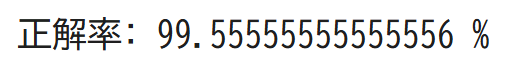
正解率が99.5%ととても高い数値が出ましたね。これは、学習データと同じような画像データを渡したときの正解率だからです。
次回は、数字の画像を読み込んで表示をさせてみましょう!