
前回までの学習ではアヤメのデータセットを処理する方法を学んでいました!
今回からは、架空のサンプルデータを自動生成する方法について学んできましょう!
目次
sklearnを使ったデータセットの自動生成
以前にも少し紹介がありましたが、scikit-learnではデータセットを自動生成することができます。
実際にパラメータを指定することで好きな形の「架空のサンプルデータ」を自動で生成することができるのです!
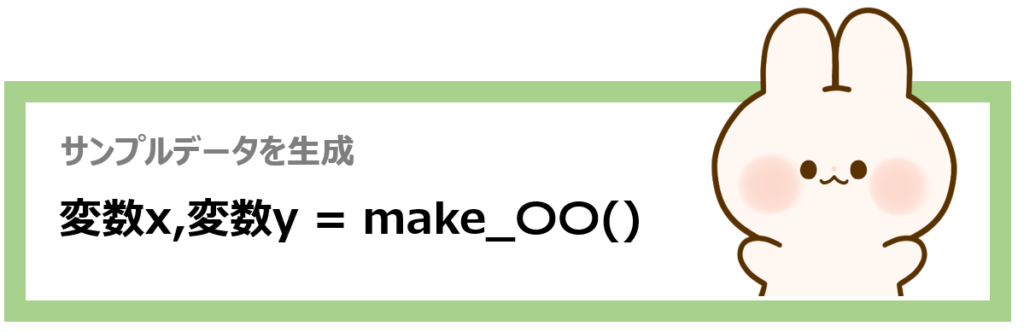
上の命令文を使って以下のようなデータを生成することができます。
| データセットの種類 | 命令 |
|---|---|
| 塊(分類用) | make_blobs(パラメータ) |
| 三日月(分類用) | make_moons(パラメータ) |
| 二重円(分類用) | make_circles(パラメータ) |
| 同心円(分類用) | make_gaussian_quantiles(パラメータ) |
| 回帰用データセット | make_regression(パラメータ) |
分類用データセットの自動生成をしよう【塊】
make_blobs()命令で「複数の塊に分かれるデータセット」を自動で生成することができます!
パラメータで
・データの個数
・特徴量
・塊の数
・ばらつきの大きさ など
を調整することができます。
データセットを自動生成できるというとても便利な機能ですが、毎回ランダムにデータが変わってしまうと、結果を比べたいときにデータが違うので比較ができなかったり、バグを見つける際に時間がかかってしまうなどと、少し困ったことになってしまいます…。
そこで便利なのがrandom_stateです!
これは、ランダム生成の出発点となる「種」を指定でき、何度実行して同じデータが生成されるのです!
以下の変数を用いて実際にコードを書いていきましょう!
| 変数名 | 意味 |
|---|---|
| random_state | ランダム生成の種を指定 |
| n_samples | データの個数 |
| n_features | 特徴量の数 |
| centers | 塊の数 |
| cluster_std | ばらつきの大きさ(標準偏差) |
①塊の数が2つのデータを作ろう
ランダムの種 = 4
特徴量 = 2
塊の数 = 2
ばらつき = 1
点の数 = 300
のデータセットを作ってみましょう!
コード
from sklearn.datasets import make_blobs
import pandas as pd
X, y = make_blobs(
random_state=4, #1
n_features=2, #2
centers=2, #3
cluster_std=1, #4
n_samples=300) #5
df = pd.DataFrame(X) # 6
df["target"] = y # 7
df.head()
#1 ランダムの種 = 4
#2 特徴量の数 = 2
#3 塊の数 = 2
#4 ばらつき = 1
#5 点の数 = 300
#6 特徴量Xでデータフレームを作成
#7 分類yをtargetの列として追加参考資料:Python3年生機械学習のしくみ
実行結果
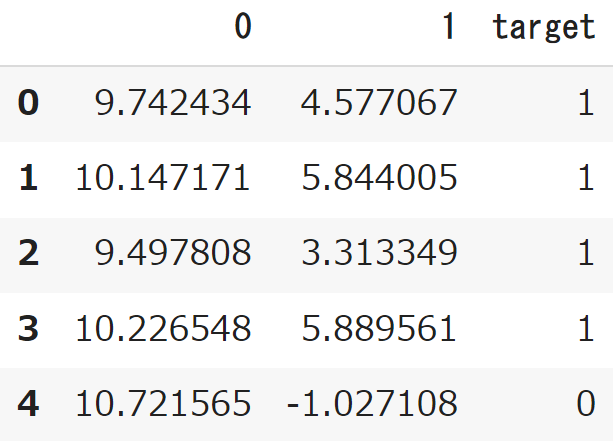
設定した値のデータが生成されました!
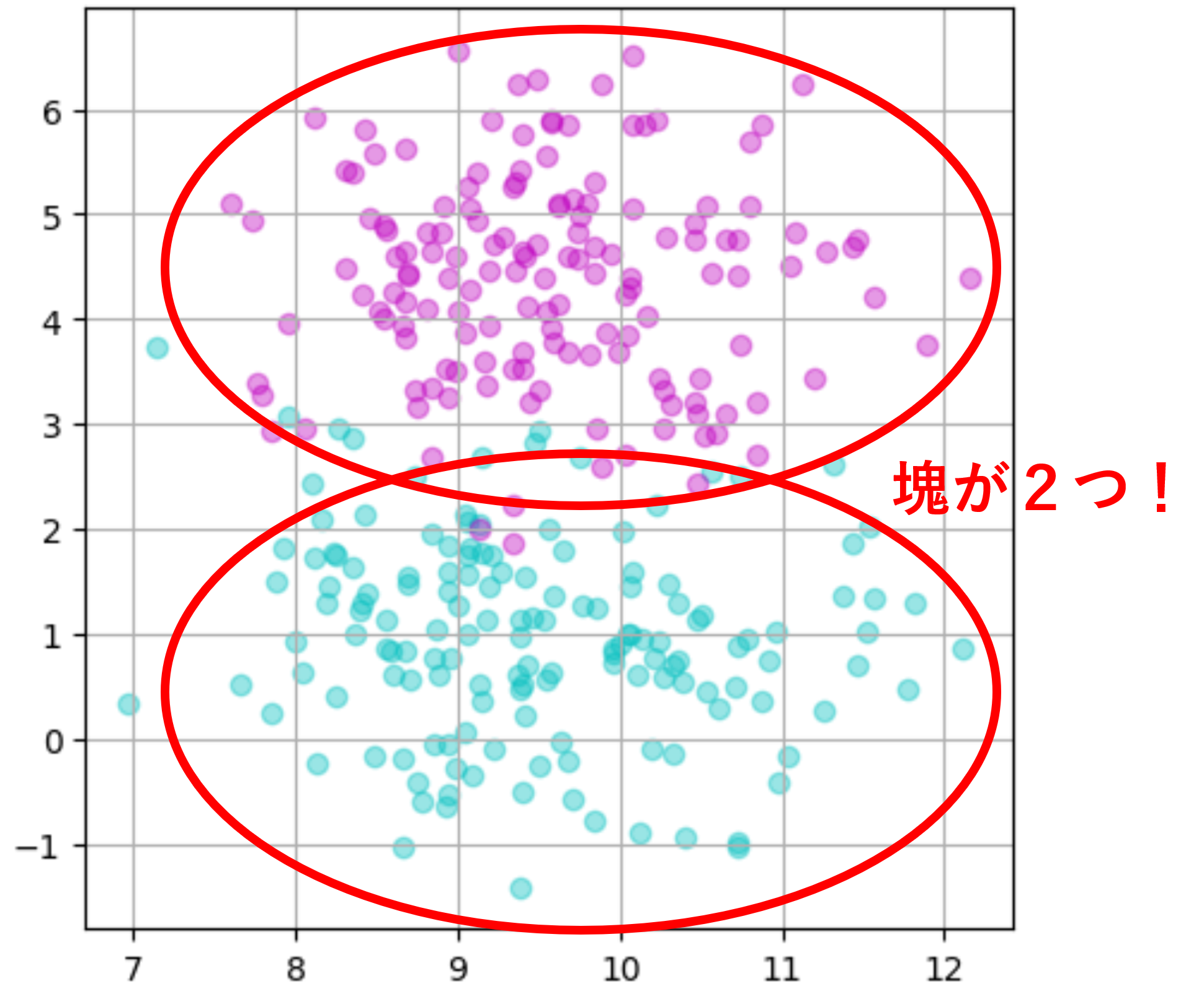
では、このデータの特徴量0を横軸に、特徴量1を縦軸に設定し、targetの値で色分けした散布図を表示しましょう!
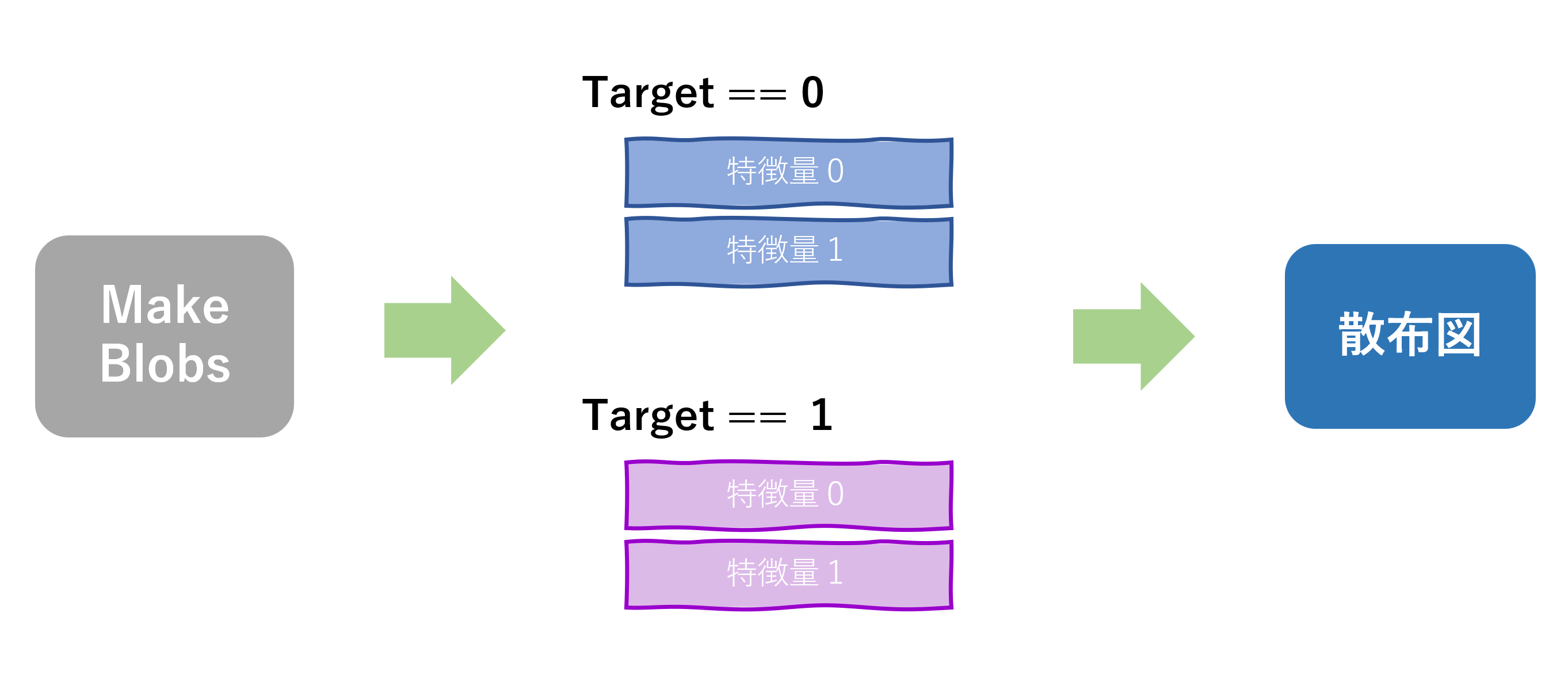
コード
%matplotlib inline
import matplotlib.pyplot as plt
df0 = df[df["target"]==0] #1
df1 = df[df["target"]==1] #2
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.4) #3
plt.scatter(df1[0], df1[1], color="m", alpha=0.4) #4
plt.grid()
plt.show()
#1~2 分類別にデータフレームを分ける
#3 シアンの散布図
#4 マゼンタの散布図参考資料:Python3年生機械学習のしくみ
実行結果
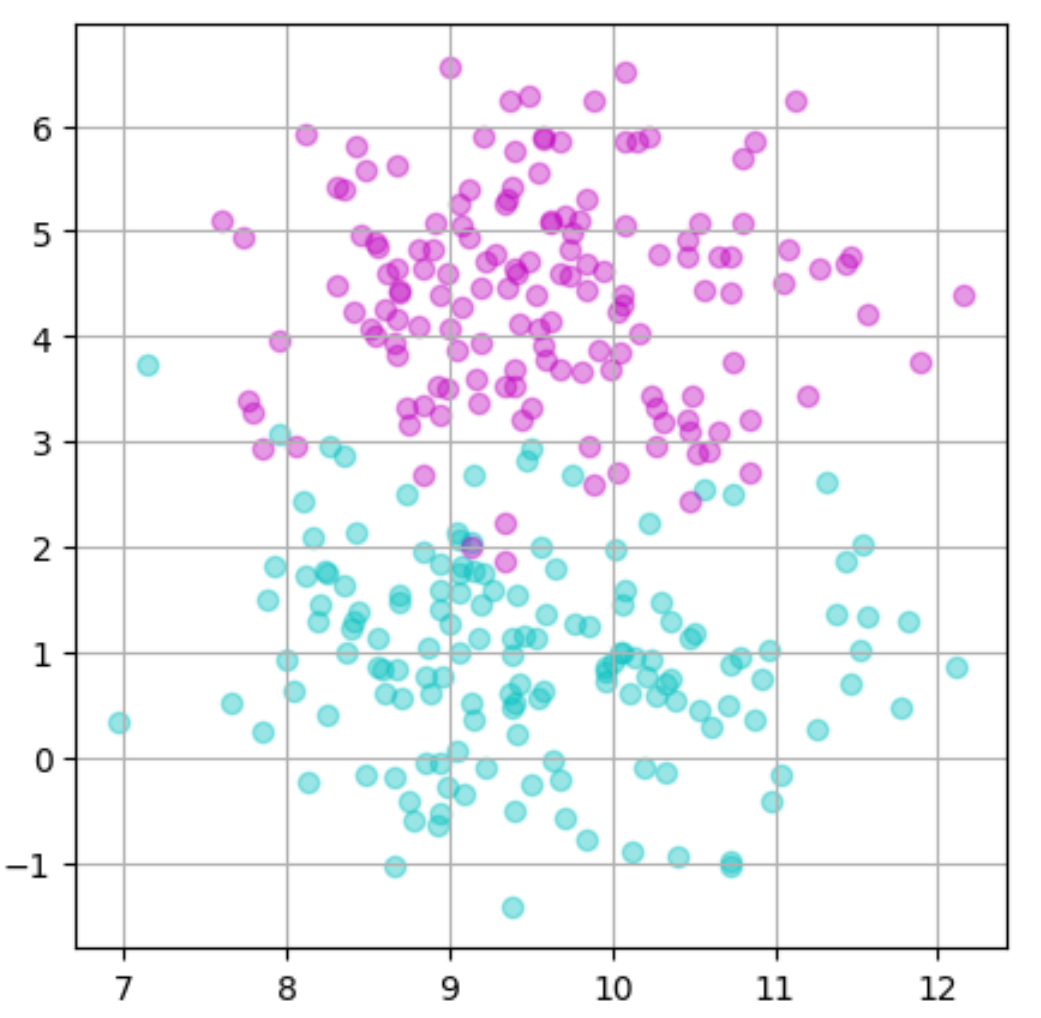
これで塊の数が2つのデータの内容を確認することが出来ました!
次回は塊の数を増やして確認してみましょう!