
前回は塊型のデータセットの生成方法について学びました
今回は三日月型のデータセットの生成方法について学習しましょう!
目次
分類用データセットの自動生成をしよう【三日月】
make_moons()命令で「三日月形の塊が組み合わせたデータセット」を自動で生成することができます!
パラメータで
・データの個数
・ノイズ
・ランダム生成の種
を指定して毎回同じ形のランダムデータにすることができます。
以下の変数を用いて実際にコードを書いていきましょう!
| 変数名 | 意味 |
|---|---|
| random_state | ランダム生成の種を指定 |
| n_samples | データの個数 |
| noise | ノイズ |
①ノイズ0.1のデータを作ろう
ランダムの種 = 4
ノイズ = 0.1
点の数 = 300
を指定してノイズが0.1の三日月型のデータセットを作ってみましょう!
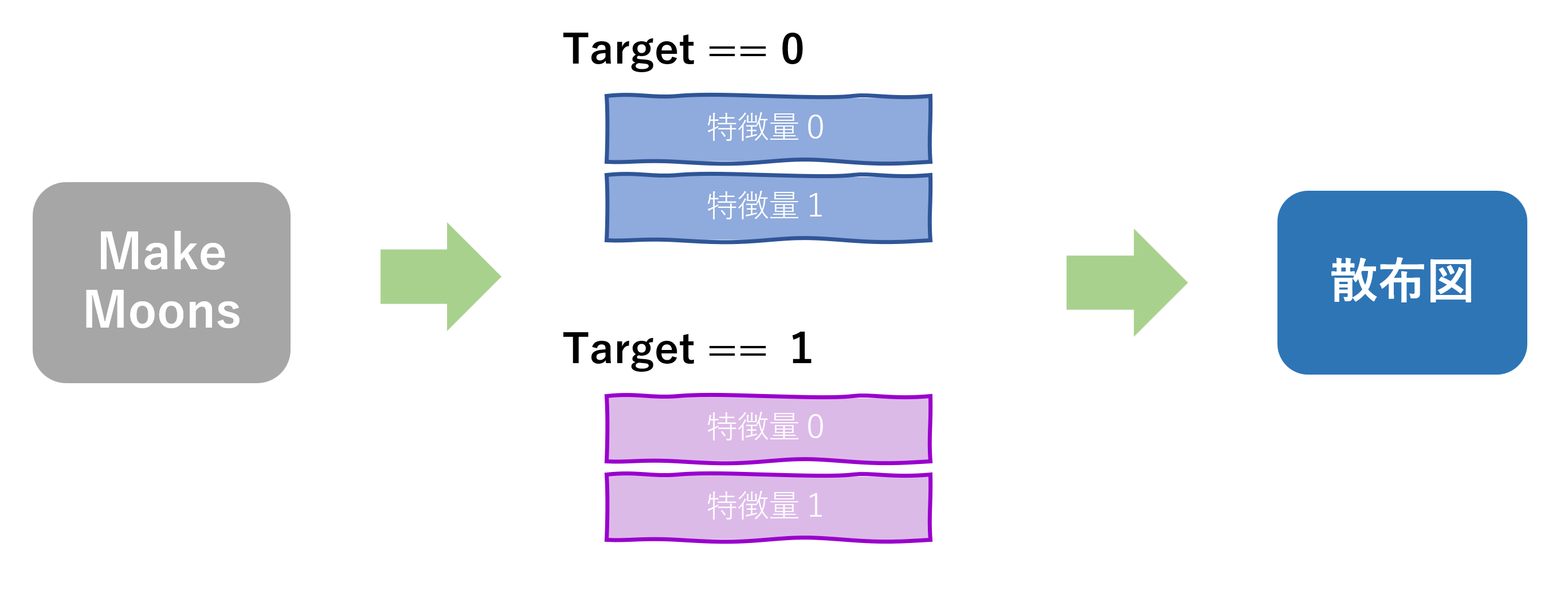
コード
#1~2 分類別にデータフレームを分ける
#3~4 シアンとマゼンタの散布図を作成
from sklearn.datasets import make_moons
X, y = make_moons(
random_state=4,
noise=0.1,
n_samples=300)
df = pd.DataFrame(X)
df["target"] = y
df0 = df[df["target"]==0] #1
df1 = df[df["target"]==1] #2
# 分類0は青、分類1は赤で、散布図を描画
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.4) #3
plt.scatter(df1[0], df1[1], color="m", alpha=0.4) #4
plt.grid()
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
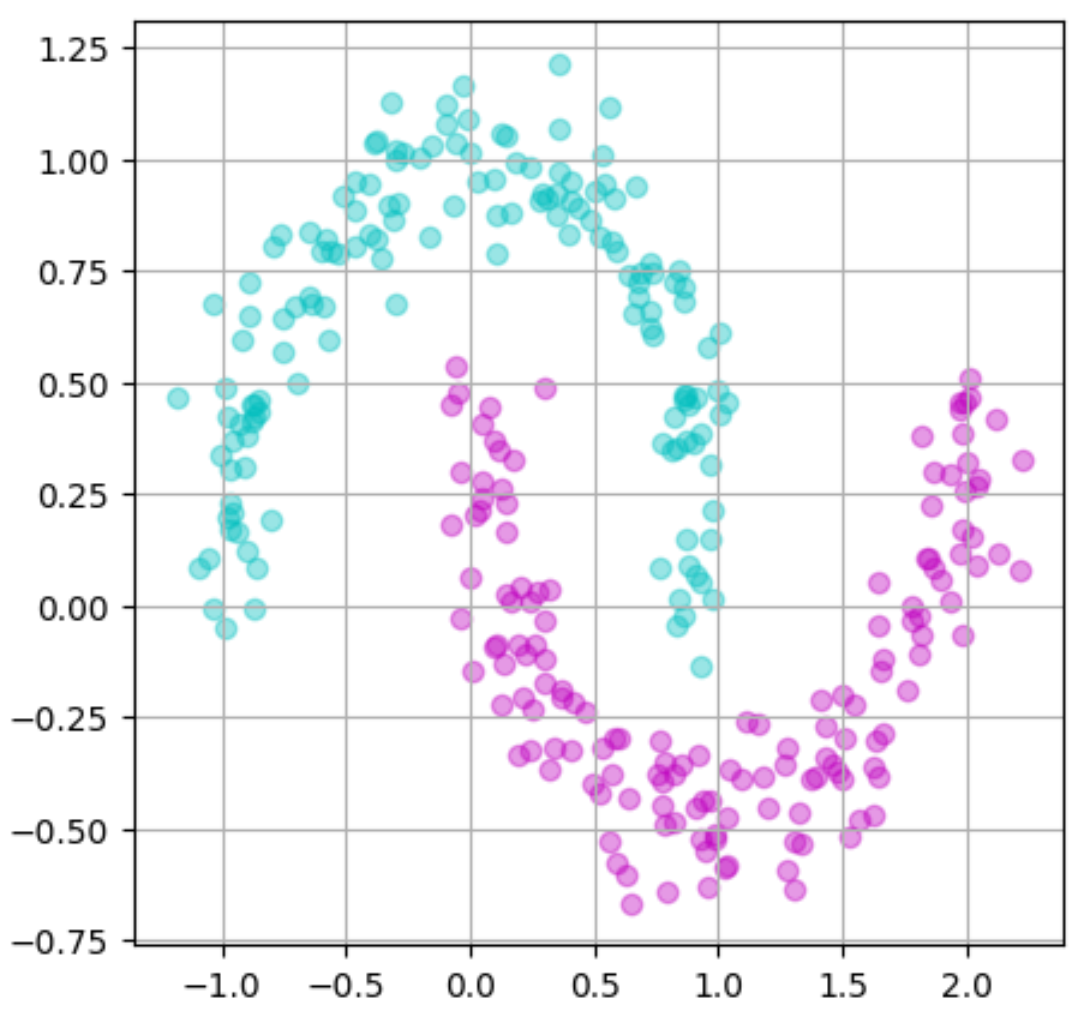
これで三日月型のデータを生成することが出来ました!
次はノイズが0のデータを生成してみましょう!
②ノイズ0のデータを作ろう
また同じ条件で、ノイズ=0に変更し、データセットを作りましょう!
もう変更方法が理解できた方は次のサンプルコードを見ずに作成してみましょう!
コード
#1 ノイズを0に変更
X, y = make_moons(
random_state=4,
noise=0, #1
n_samples=300)
df = pd.DataFrame(X)
df["target"] = y
df0 = df[df["target"]==0]
df1 = df[df["target"]==1]
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.4)
plt.scatter(df1[0], df1[1], color="m", alpha=0.4)
plt.grid()
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果

線のように見えるデータが生成されましたね!
③ノイズ0.3のデータを作ろう
また同じ条件で、ノイズ=0.3に変更し、データセットを作りましょう!
もう変更方法が理解できた方は次のサンプルコードを見ずに作成してみましょう!
コード
#1 ノイズを0.3に変更
X, y = make_moons(
random_state=3,
noise=0.3, #1
n_samples=300)
df = pd.DataFrame(X)
df["target"] = y
df0 = df[df["target"]==0]
df1 = df[df["target"]==1]
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.4)
plt.scatter(df1[0], df1[1], color="m", alpha=0.4)
plt.grid()
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
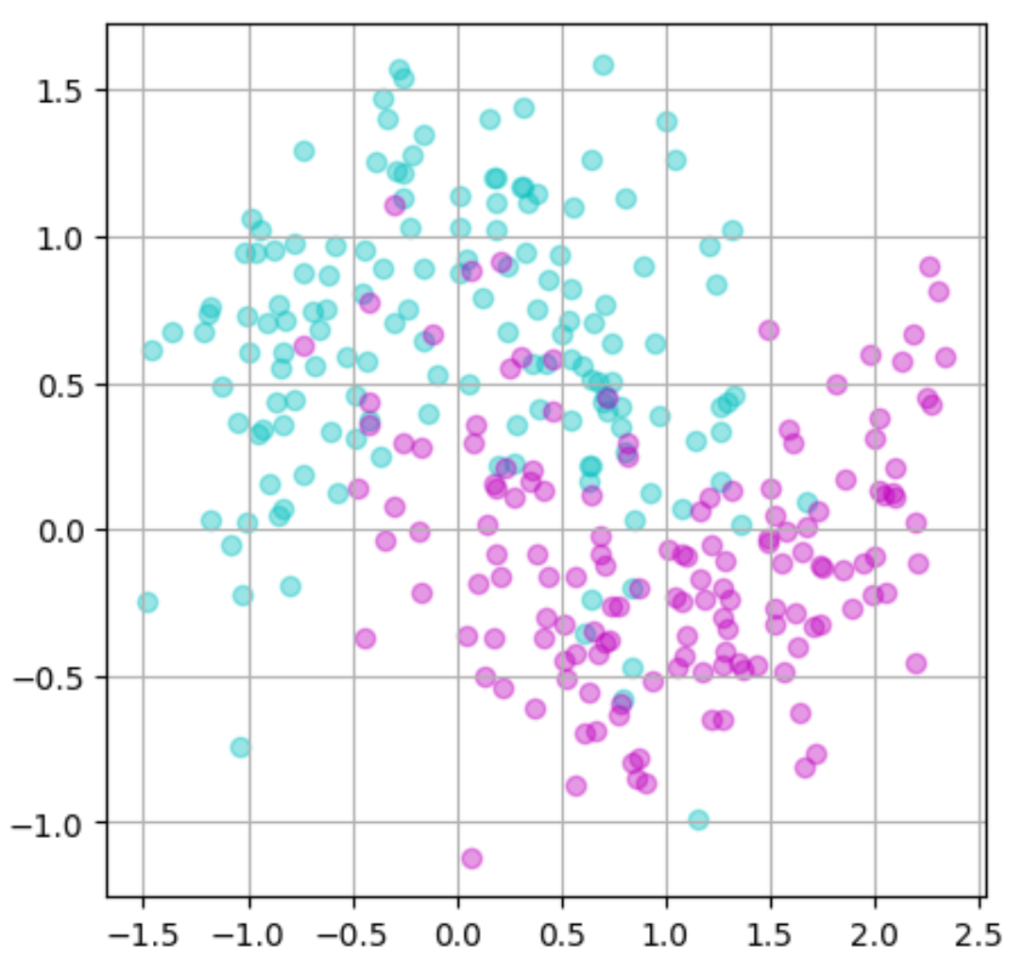
三日月型に見えないほどのばらつきになってしましましたね。
このようにノイズの値を変更するだけでこんなにもデータが変わることがわかりました!
確認問題
ランダムの種 = 3
ノイズ = 0.2
点の数 = 300
の三日月型のデータセットを作成して、青と赤の散布図を半透明で描画してみましょう。
答えはコチラをクリック!
答え:
from sklearn.datasets import make_moons
X, y = make_moons(
random_state=3,
noise=0.2,
n_samples=300)
df = pd.DataFrame(X)
df["target"] = y
df0 = df[df["target"]==0]
df1 = df[df["target"]==1]
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="b", alpha=0.5)
plt.scatter(df1[0], df1[1], color="r", alpha=0.5)
plt.grid()
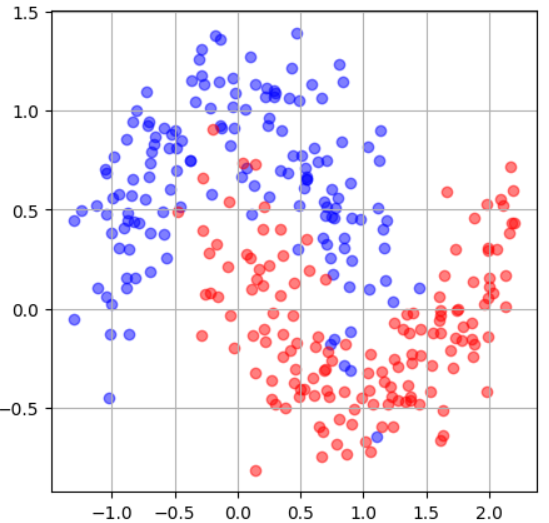
plt.show()ヒント
このような散布図になるはずです!
次回は二重円のデータセットを作成する方法を学んでいきましょう!