前回は三日月型のデータセットの生成方法について学びました
今回は分類用のデータセットではなく、回帰用のデータセットの自動生成について学びましょう!
分類と回帰の違いは?
前回までは分類用データセットについて学習していましたが、今回は回帰用データセットについて学びます。
では、分類用と回帰用では何が違うのでしょうか?
分類とは
あるデータがどの分類に当てはまるかを予測する
つまり、YESかNOかで分ける
回帰とは
ある値に関係する値がどんな数値になるかを予測する
データの図を用いると
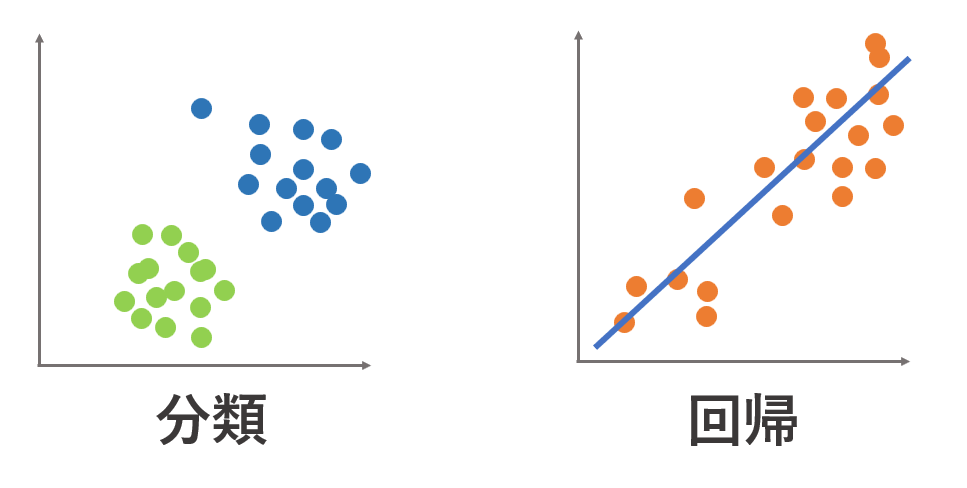
のイメージです!
回帰用データセットの自動生成をしよう
make_regression()命令で「回帰のデータセット」を自動で生成することができます!
パラメータは
・データの個数
・特徴量の数
・ノイズ
・y切片
・ランダム生成の種
を指定して毎回同じ形のランダムデータにすることができます。
以下の変数を用いて実際にコードを書いていきましょう!
| 変数 | 意味 |
|---|---|
| n_samples | データの個数 |
| n_features | 特徴量の数 |
| noise | ノイズ |
| bias | y切片 |
| random_state | ランダム生成の種 |
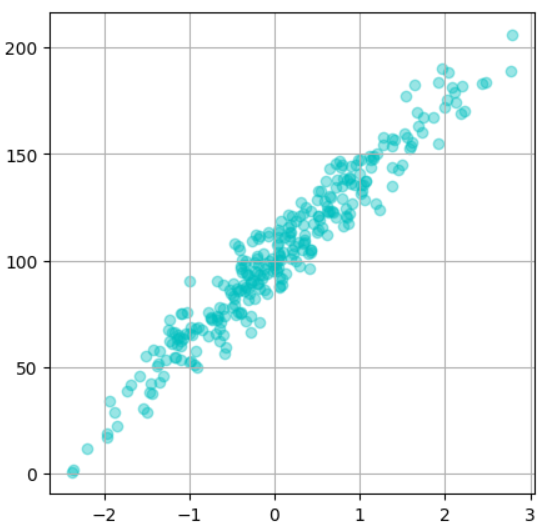
①ノイズ10のとき(X, Y)=(0, 100)を通るデータセット
ランダムの種 = 4
特徴量=1
ノイズ = 10
y切片=100
点の数 = 300
を指定してノイズが10のとき、(X, Y)=(0, 100)を通る線のデータセットを作ってみましょう!
コード
#1 ノイズ10
#2 y切片100
#3 シアンの散布図
from sklearn.datasets import make_regression
X, y = make_regression(
random_state=4,
n_features=1,
noise=10, #1
bias = 100, #2
n_samples=300)
df = pd.DataFrame(X)
plt.figure(figsize=(5, 5))
plt.scatter(df[0], y, color="c", alpha=0.4) #3
plt.grid()
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
②ノイズ0のとき(X, Y)=(0, 100)を通るデータセット
ランダムの種 = 4
特徴量=1
ノイズ = 0
y切片=100
点の数 = 300
を指定してノイズが0のとき、(X, Y)=(0, 100)を通る線のデータセットを作ってみましょう!
コード
#1 ノイズ0
from sklearn.datasets import make_regression
X, y = make_regression(
random_state=4,
n_features=1,
noise=0, #1
bias = 100,
n_samples=300)
df = pd.DataFrame(X)
plt.figure(figsize=(5, 5))
plt.scatter(df[0], y, color="c", alpha=0.4)
plt.grid()
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
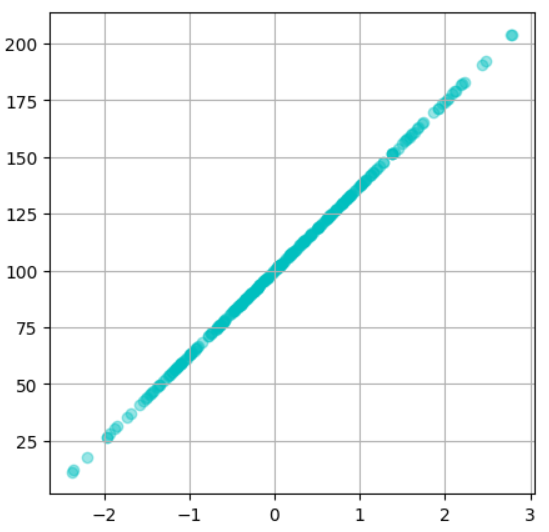
このようにノイズを指定し、回帰用のデータセットを用意することができました!
データセットを自動生成し用意することで、学習モデルをテストするときなどのとても便利な場面で利用することができるのです!
確認問題
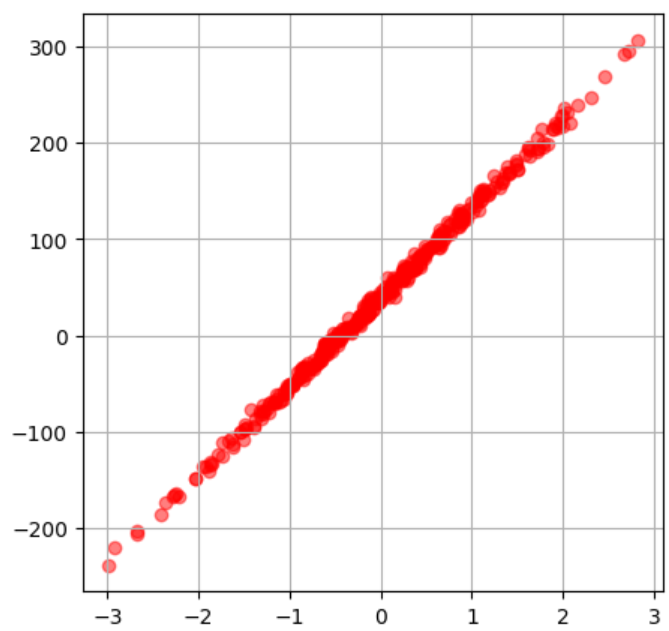
ランダムの種=3
特徴量=1
ノイズ=5
y切片= 40
点の数= 400
のXが0のときyが40を通る線のデータセットを作成して、赤の散布図を半透明で描画してみましょう。
答えはコチラをクリック!
答え:
from sklearn.datasets import make_regression
X, y = make_regression(
random_state = 3,
n_features = 1,
noise = 5,
bias = 40,
n_samples=400)
df = pd.DataFrame(X)
plt.figure(figsize=(5, 5))
plt.scatter(df[0], y, color="r", alpha=0.5)
plt.grid()
plt.show()ヒント
このような散布図になるはずです!