
前回紹介した機械学習の手順に従って今回は、➁データを学習用とテスト用に分ける方法について学びましょう。
目次
データを分ける意味
学習用データ
賢くなるために学習させるデータ
たくさんのデータを見せることで、そのデータの内容や特徴を覚えます。
テスト用データ
ちゃんと学習できてるいるのかを評価するためのデータ
学習の精度を予測するために使います。
学習用データとテスト用データが分けれている理由としては、学習した精度をしっかりと評価・確認するためです。
学習用データを用いて特徴をつかみ、そのあとにまだ学習してないデータを渡すことで、未知のデータに対しても正しく予測できるかどうか、学習用データだけに過度に対応しすぎていないか(過学習)をチェックすることができます。
人間でいうところの…、テスト前に問題を丸暗記したことが将来ほんとうに役に立つのかというのを回避するためです!
ステップ2:データを学習用とテスト用に分ける
「特徴量X(説明変数)」と「分類y(目的変数)」を学習用とテスト用に分けます。
train_test_split命令を使ってデータを分割します。
これにXとyを渡し、ランダムの種を「0」に固定します。

この命令で、学習用:75%、テスト用:25%に分けられます。
| X_train | 学習用データの問題(説明変数) |
| y_train | 学習用データの答え(目的変数) |
| X_test | テスト用データの問題(説明変数) |
| y_test | テスト用データの答え(目的変数) |
コード
#1 学習用とテスト用のデータに分ける
#2~3 データフレーム:学習用の特徴量、target列:分類
#4~5 分類別のデータフレーム
#6~7 シアンとマゼンタの学習用散布図
#8~9 データフレーム:テスト用の特徴量、target列:分類
#10~11 分類別のデータフレーム
#12~13 シアンとマゼンタのテスト用散布図
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) #1
df = pd.DataFrame(X_train) #2
df["target"] = y_train #3
df0 = df[df["target"]==0] #4
df1 = df[df["target"]==1] #5
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.4) #6
plt.scatter(df1[0], df1[1], color="m", alpha=0.4) #7
plt.title("train:75%")
plt.show()
df = pd.DataFrame(X_test) #8
df["target"] = y_test #9
df0 = df[df["target"]==0] #10
df1 = df[df["target"]==1] #11
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.4) #12
plt.scatter(df1[0], df1[1], color="m", alpha=0.4) #13
plt.title("test:25%")
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
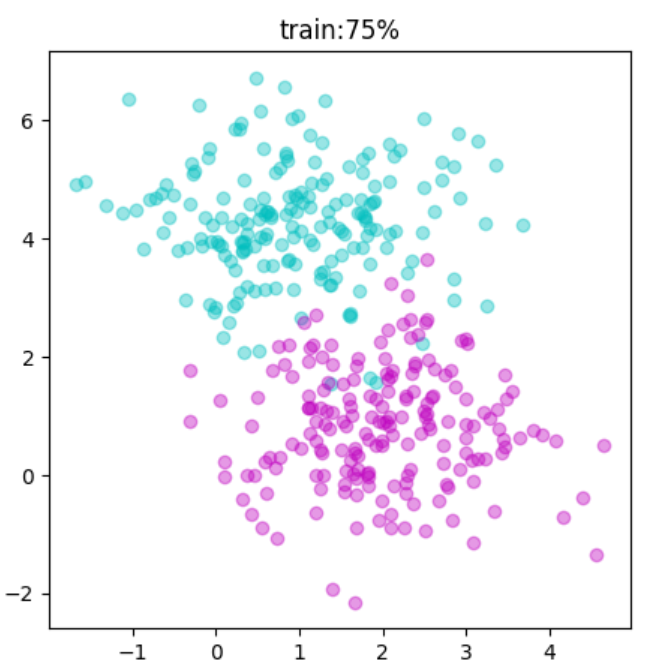
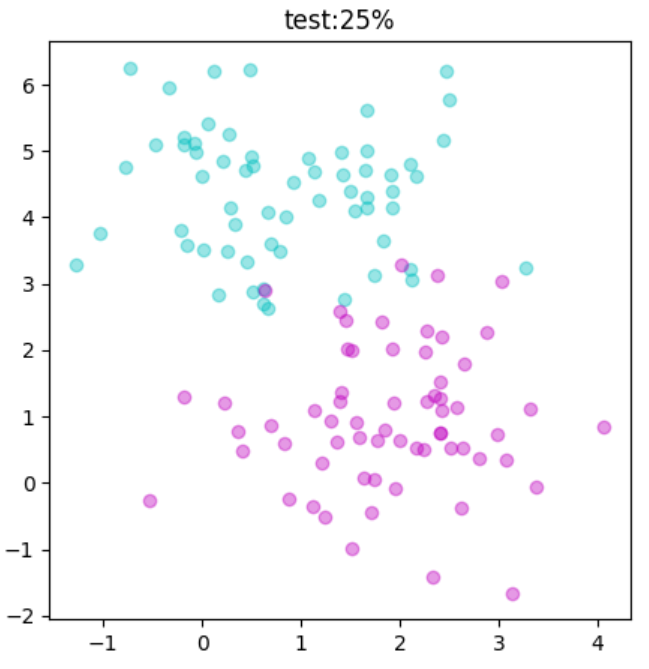
この結果の2つを見比べると点の数はもちろん、点の位置も違います。
しかし、全体的にみるとばらつき具合が見ているので「分かれ方の法則」が理解できるでしょう!