
017_機械学習の手順【データを用意】で紹介した機械学習の手順に従って今回は、④モデルをテストするについて学びましょう。
前回行った学習がちゃんと学習できているのかテストをして確認してみましょう!
以前作成したテスト用データをpredict命令を与えて答えを予測させて確認します。この予測を本当の答えと比較して正解率も出してみましょう!
目次
テスト用データを使って予測する
まず、predict命令にX_testを与えて散布図にしてみましょう!
コード
#1 テスト用データを予測する
#2~3 特徴量X_testでデータフレームを作成&予測結果predをtargetの列に
pred = model.predict(X_test) #1
df = pd.DataFrame(X_test) #2
df["target"] = pred #3
df0 = df[df["target"]==0]
df1 = df[df["target"]==1]
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.5)
plt.scatter(df1[0], df1[1], color="m", alpha=0.5)
plt.title("predict")
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
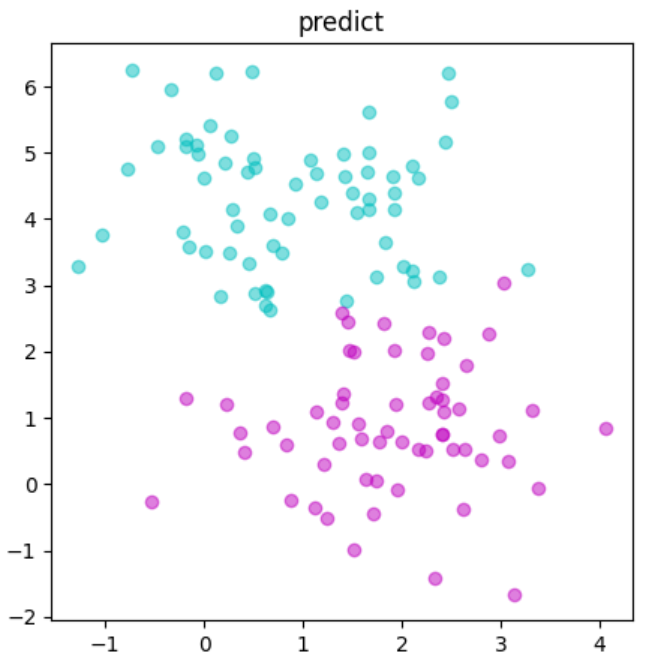
この結果をテストデータを比較してみると…
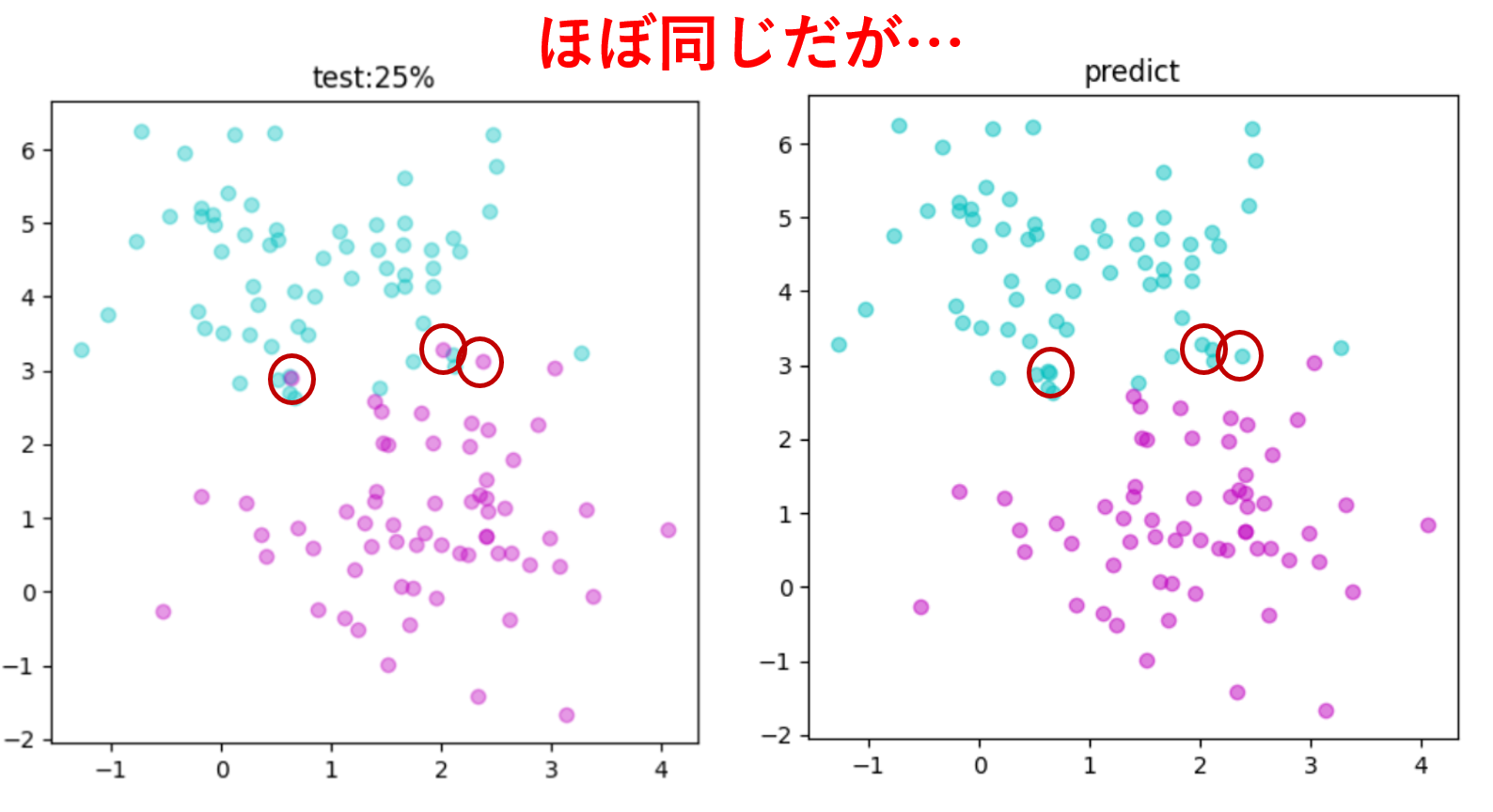
3つの点は違う結果になっていることがわかります!
このように予測とデータが違うことがあり得るのです。
正解率を出してみよう
では、この正解率を調べてみましょう!
accuracy_score命令に正解のデータと予測のデータを与えるとどのくらいの確率で正解しているのかを確認することが出来ます。
コード
#1 正解率を調べる
from sklearn.metrics import accuracy_score
pred = model.predict(X_test) #1
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")参考資料:Python3年生機械学習のしくみ
実行結果

97.6%であることがわかりました!まあまあな正解率ですね…
次回では新しい値を与えて予測を行っていきます!