
今回は017~021までで学んだ機械学習の手順をしっかりと学べているかテストをしていきたいと思います!自信のない方は017_機械学習の手順【データを用意】から再度復習してから挑んでみましょう!
目次
確認問題1
機械学習を行う正しいステップを以下の選択肢から選びましょう。
①
STEP
データを用意する
STEP
モデルを選び学習する
STEP
データを学習用とテスト用に分ける
STEP
モデルをテストする
STEP
値を用意して予測する
➁
STEP
データを用意する
STEP
データを学習用とテスト用に分ける
STEP
モデルをテストする
STEP
モデルを選び学習する
STEP
値を用意して予測する
③
STEP
データを用意する
STEP
モデルを選び学習する
STEP
モデルをテストする
STEP
データを学習用とテスト用に分ける
STEP
値を用意して予測する
④
STEP
データを用意する
STEP
データを学習用とテスト用に分ける
STEP
モデルを選び学習する
STEP
モデルをテストする
STEP
値を用意して予測する
答え
④
STEP
データを用意する
STEP
データを学習用とテスト用に分ける
STEP
モデルを選び学習する
STEP
モデルをテストする
STEP
値を用意して予測する
このステップを繰り返して精度の高い機械学習をいっていくのです!
確認問題2
新規のノートブックを作成して、
ランダムの種:4
特徴量:2
塊数:2
ばらつき:1
点の数:300
の2つの塊のデータを作成しましょう。
また、特徴量(X)でデータフレームを作成し、分類(y)をtargetの列として追加しましょう。
答え
コード
#1 ランダムの種:4
#2 特徴量:2
#3 塊数:2
#4 ばらつき:1
#5 点の数:300
#6 特徴量Xでデータフレームを作り、分類yをtargetの列とする
from sklearn.datasets import make_blobs
import pandas as pd
X, y = make_blobs(
random_state=4, #1
n_features=2, #2
centers=2, #3
cluster_std=1, #4
n_samples=300) #5
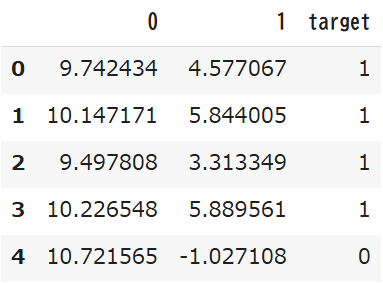
df = pd.DataFrame(X) #6
df["target"] = y
df.head()実行結果
確認問題3
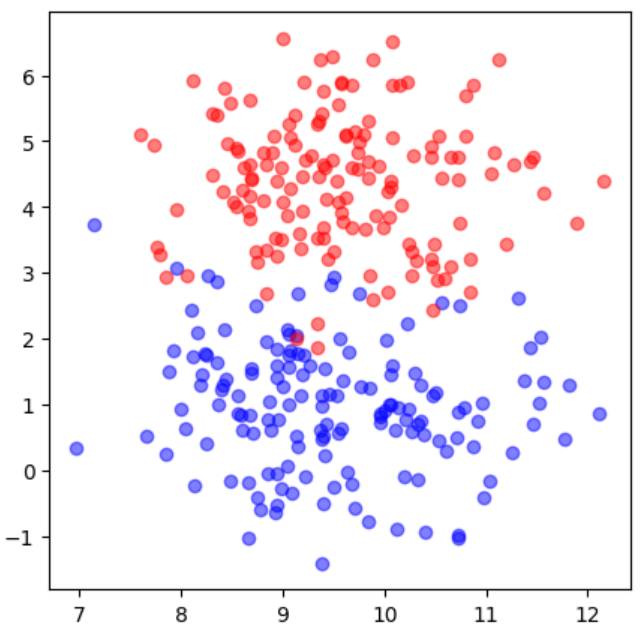
確認問題2で作成したデータを散布図で確認してみましょう。
このとき、青と赤の半透明の点で構成された散布図を作成しましょう。
答え
コード
#1~2 分類別にデータフレームに分ける
#3~4 青と赤の散布図
import matplotlib.pyplot as plt
%matplotlib inline
# 分類によって、別々のデータフレームに分ける
df0 = df[df["target"]==0] #1
df1 = df[df["target"]==1] #2
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="b", alpha=0.5) #3
plt.scatter(df1[0], df1[1], color="r", alpha=0.5) #4
plt.show()実行結果
確認問題4
データを
学習用:75%
テスト用:25%
に分けて確認問題3の条件と同じように散布図に表示してみましょう。
答え
コード
#1 学習用とテスト用のデータに分ける
#2~3 データフレーム:学習用の特徴量、target列:分類
#4~5 分類別のデータフレーム
#6~7 青と赤の学習用散布図
#8~9 データフレーム:テスト用の特徴量、target列:分類
#10~11 分類別のデータフレーム
#12~13 青と赤のテスト用散布図
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) #1
df = pd.DataFrame(X_train) #2
df["target"] = y_train #3
df0 = df[df["target"]==0] #4
df1 = df[df["target"]==1] #5
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="b", alpha=0.5) #6
plt.scatter(df1[0], df1[1], color="r", alpha=0.5) #7
plt.title("train:75%")
plt.show()
df = pd.DataFrame(X_test) #8
df["target"] = y_test #9
df0 = df[df["target"]==0] #10
df1 = df[df["target"]==1] #11
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="b", alpha=0.5) #12
plt.scatter(df1[0], df1[1], color="r", alpha=0.5) #13
plt.title("test:25%")
plt.show()実行結果


確認問題5
SVMを使って機械学習を行ってみましょう。
答え
コード
#1 サポートベクターマシンで学習モデルを作る
#2 学習用データを渡して学習する
from sklearn import svm
model = svm.SVC() #1
model.fit(X_train, y_train) #2実行結果

確認問題6
分けていたテスト用データ(X_test)をある命令に渡して答えを予測させてみましょう。また、元のテストデータと比べて何個の点が間違えて予測されているか数えてみましょう。
答え
コード
#1 テスト用データを予測する
#2~3 特徴量X_testでデータフレームを作成&予測結果predをtargetの列に
pred = model.predict(X_test) #1
df = pd.DataFrame(X_test) #2
df["target"] = pred #3
df0 = df[df["target"]==0]
df1 = df[df["target"]==1]
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="b", alpha=0.5)
plt.scatter(df1[0], df1[1], color="r", alpha=0.5)
plt.title("predict")
plt.show()実行結果
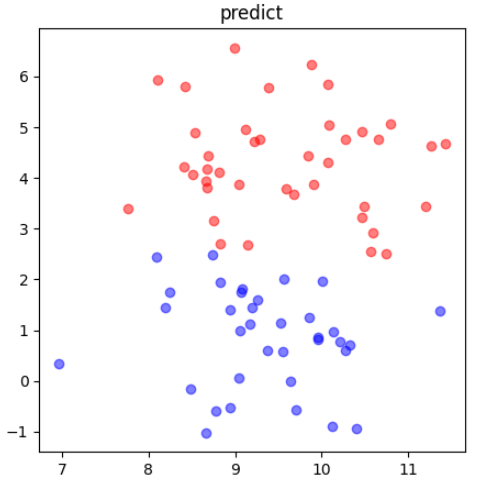
間違えて予測されている点の数は3つでした!

確認問題7
正解率を調べてみましょう。
答え
コード
#1 正解率を調べる
from sklearn.metrics import accuracy_score
pred = model.predict(X_test) #1
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")実行結果

確認問題8
新たなデータ
①説明変数「9と2」
➁説明変数「10と2」
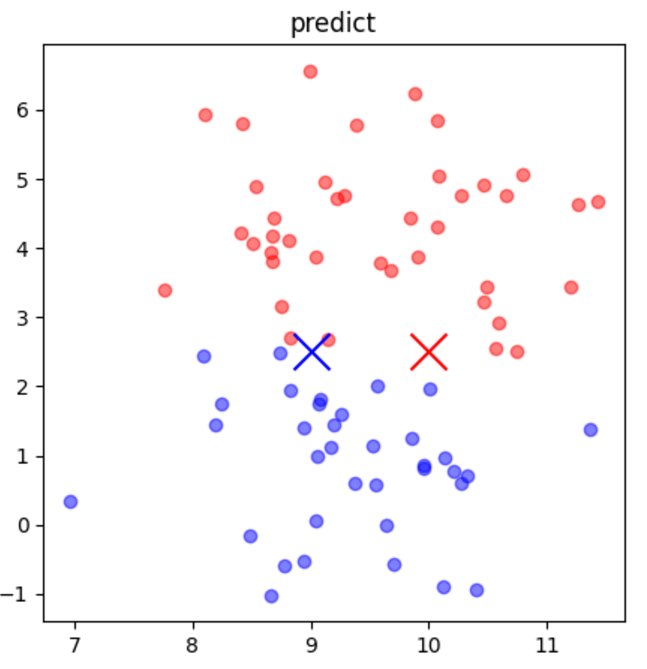
を与えて予測して予測結果を実際に散布図にXマークとしてかいてみましょう。
答え
コード
#1 説明変数「9と2.5」の結果を予測
#2 説明変数「10と2.5」の結果を予測
#3 散布図上に[9,2.5][10,2.5]の位置にXを描画
pred = model.predict([[9,2.5]]) #1
print("9,2.5=",pred)
pred = model.predict([[10,2.5]]) #2
print("10,2.5=",pred)
#3
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="b", alpha=0.5)
plt.scatter(df1[0], df1[1], color="r", alpha=0.5)
plt.scatter([9], [2.5], color="b", marker="x", s=300)
plt.scatter([10], [2.5], color="r", marker="x", s=300)
plt.title("predict")
plt.show()実行結果
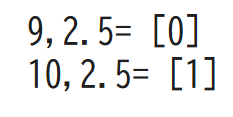
これで機械学習の仕方の復讐は完璧です!
次回から機械学習がどのように分類を行っているのか可視化してみる方法について学習しましょう!