前回用意したデータセットを用いて学習と予測を行ってみましょう!
目次
線形回帰のモデルに学習させて予測
データを訓練データと学習データに分けてモデルに学習させてみましょう!
コード
#1 訓練データとテストデータに分ける
#2 学習データを使って線形回帰の学習モデルを作る
#3 テストデータを使って正解率を調べる
#4 散布図上にたくさんの予測の点を書いて線にする
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) #1
model = LinearRegression() #2
model.fit(X_train, y_train)
pred = model.predict(X_test) #3
score = r2_score(y_test, pred)
print("正解率:", score*100, "%")
plt.figure(figsize=(5, 5)) #4
plt.scatter(X, y, color="b", alpha=0.5)
plt.plot(X, model.predict(X), color = 'red')
plt.grid()
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
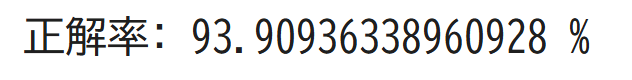
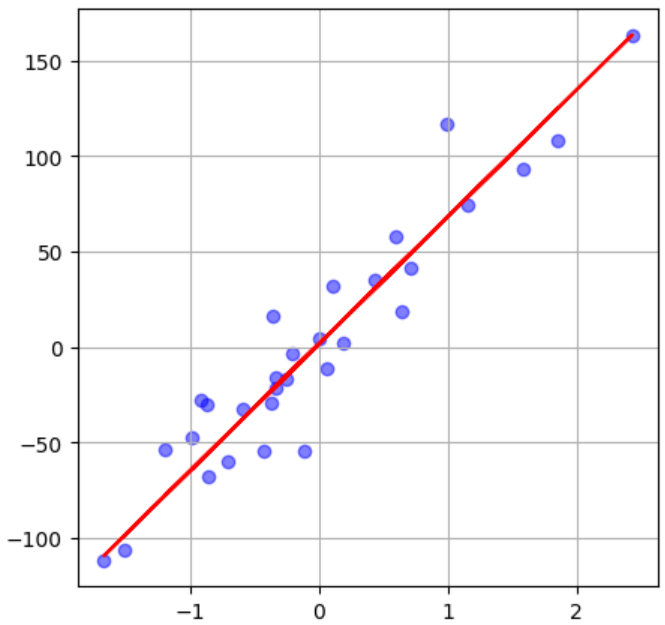
きれいな線を引くことができました!正解率も約94%と高い結果を出すことができましたね!
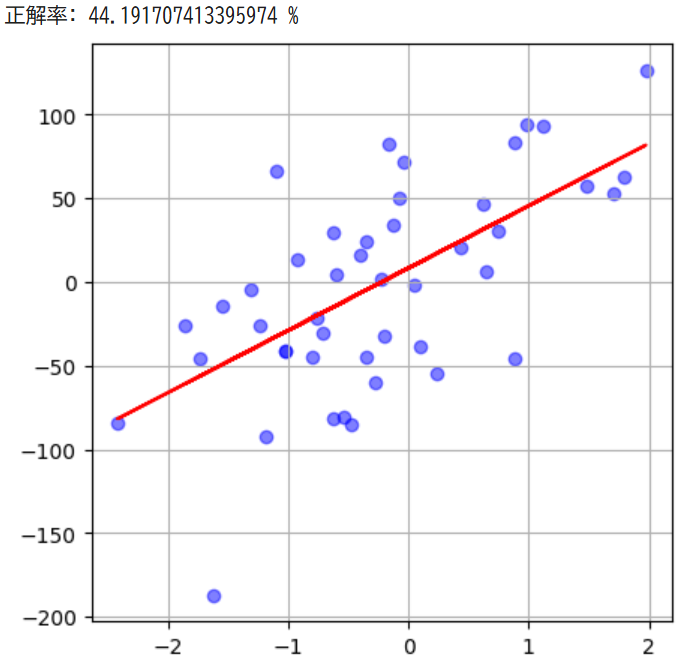
ノイズが大きい場合は…?
もっとばらつきの多い場合を確認してみましょう!
コード
#1 ノイズ:80に変更
#2 訓練データ、テストデータに分ける
#3 訓練データを使って線形回帰の学習モデルを作成
#4 テストデータを使って正解率を調べる
#5 散布図上にたくさんの予測の点を書いて線にする
X, y = make_regression( #1
random_state=5,
n_samples=30,
n_features=1,
noise=80)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) #2
model = LinearRegression() #3
model.fit(X_train, y_train)
pred = model.predict(X_test) #4
score = r2_score(y_test, pred)
print("正解率:", score*100, "%")
plt.figure(figsize=(5, 5)) #5
plt.scatter(X, y, color="b", alpha=0.5)
plt.plot(X, model.predict(X), color = 'red')
plt.grid()
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
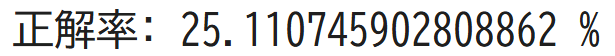
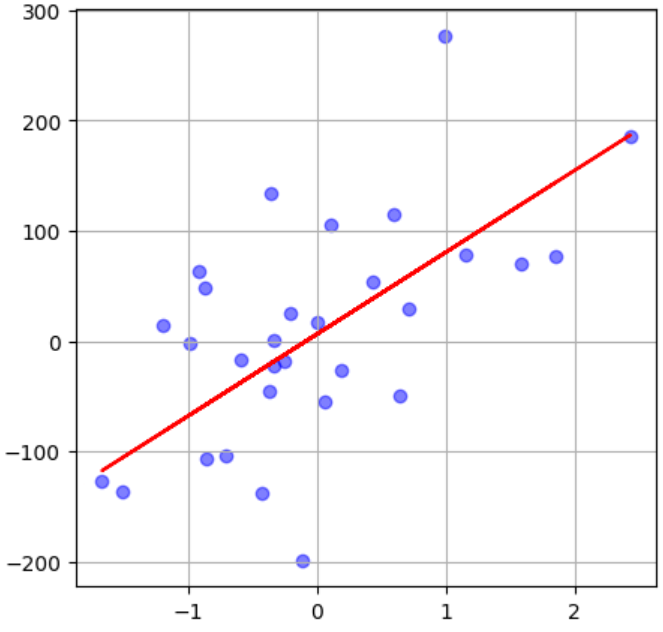
線を引くことはできましたが、正解率が約25%と低い線を引いてしまいました…。このようにノイズが大きいデータだと予測が難しいのです。
確認問題
ランダムの種:3
特徴量:1
ノイズ:50
点の数:45
に変更して線形回帰モデルの正解率を確認しましょう。
答えはコチラをクリック!
答え:
X, y = make_regression( #1
random_state=3,
n_features=1,
noise=50,
n_samples=45)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) #2
model = LinearRegression() #3
model.fit(X_train, y_train)
pred = model.predict(X_test) #4
score = r2_score(y_test, pred)
print("正解率:", score*100, "%")
plt.figure(figsize=(5, 5)) #5
plt.scatter(X, y, color="b", alpha=0.5)
plt.plot(X, model.predict(X), color = 'red')
plt.grid()
plt.show()ヒント
このような散布図になるはずです!