前回用意したデータセットを用いて学習と予測を行ってみましょう!
目次
ロジスティック回帰のモデルに学習させて予測
データを訓練データと学習データに分けてモデルに学習させてみましょう!
コード
#1 訓練データ、テストデータに分ける
#2 訓練データを使ってロジスティック回帰の学習モデルを作成
#3 テストデータを使って正解率を調べる
#4 テストデータを使ってこの学習モデルの分類の様子を表示する
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = LogisticRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")
df = pd.DataFrame(X_test)
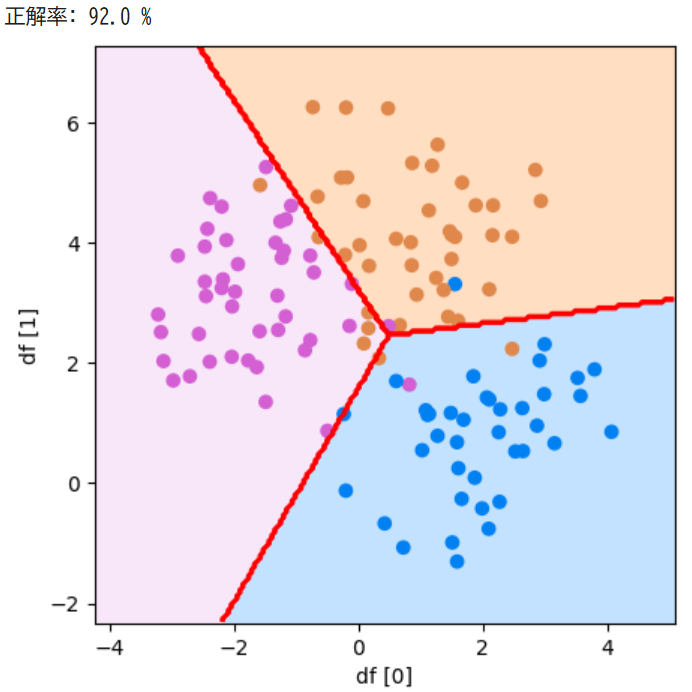
plot_boundary(model, df[0], df[1], y_test, "df [0]", "df [1]")参考資料:Python3年生機械学習のしくみ
実行結果


正解率100%の2つをきれいに分ける線を引くことができました!
3つに分類するとき
塊数を3つに増やしたときのモデルの学習について確認してみましょう。
コード
#1 ランダムの種:3、特徴量:2、塊数:3、ばらつき:1、点の数:300個のデータセットを作成
#2 訓練データ、テストデータに分ける
#3 訓練データを使ってロジスティック回帰の学習モデルを作成
#4 テストデータを使って正解率を調べる
#5 テストデータを使ってこの学習モデルの分類の様子を表示する
X, y = make_blobs( #1
random_state=3,
n_features=2,
centers=3,
cluster_std=1,
n_samples=300)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) #2
model = LogisticRegression() #3
model.fit(X_train, y_train)
pred = model.predict(X_test) #4
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")
df = pd.DataFrame(X_test) #5
plot_boundary(model, df[0], df[1], y_test, "df [0]", "df [1]")参考資料:Python3年生機械学習のしくみ
実行結果
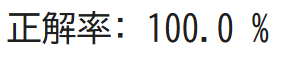
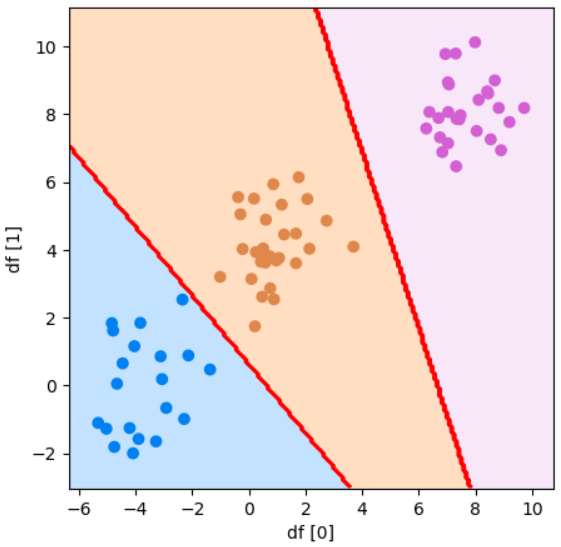
3つにも分類できるこがわかりました!
シグモイド関数について
シグモイド関数関数をグラフ化してもっと理解を深めてみましょう。

コード
#1 xの値(-10〜10を200個に分割)
#2 シグモイド関数
xx = np.linspace(-10, 10, 200) #1
yy = 1 / (1 + np.exp(-xx)) #2
plt.scatter(xx, yy, color="r")
plt.grid()
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
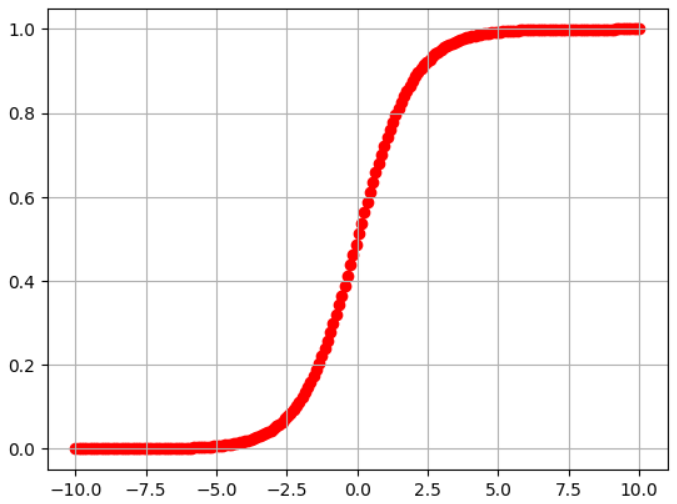
1と0を滑らかな曲線でつないでいるグラフを表示することができました!
確認問題
ランダムの種:0
特徴量:2
グループ:3
ばらつき:1
点の数:500個
の同心円型のデータセットをつかってロジスティック回帰のモデルに学習させて正解率を予測させましょう。
答えはコチラをクリック!
答え:
X, y = make_blobs(
random_state=0,
n_features=2,
centers=3,
cluster_std=1,
n_samples=500)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = LogisticRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")
df = pd.DataFrame(X_test)
plot_boundary(model, df[0], df[1], y_test, "df [0]", "df [1]")ヒント
このような散布図になるはずです!