
前回学習したSVM(サポートベクターマシン)の使い方を実際にPythonで確認してみましょう!
目次
モデルの使い方


上記の書式を用いて線形分類の場合も非線形分類の場合もsvm.SVCで作成します。学習させたモデルにpredict命令で説明変数Xを渡すと予測結果が帰ってきます。
線形分類
SVM(サポートベクターマシン)で使用するデータセットを自動生成しましょう。
ランダムの種:1
特徴量:2
塊数:3
ばらつき:2
点の数:500その後、データを分け、モデルに学習させ、テストデータでテストし、分類の状態を表示して確認してみましょう!
コード
#1 ランダムの種:1、特徴量:2、塊数:3、ばらつき:2、点の数:500個のデータセットを作成
#2 訓練データ、テストデータに分ける
#3 訓練データを使ってロジスティック回帰の学習モデルを作成
#4 テストデータを使って正解率を調べる
#5 テストデータを使ってこの学習モデルの分類の様子を表示する
from sklearn import svm
X, y = make_blobs( #1
random_state=1,
n_features=2,
centers=3,
cluster_std=2,
n_samples=500)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) #2
model = svm.SVC(kernel="linear") #3
model.fit(X_train, y_train)
pred = model.predict(X_test) #4
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")
df = pd.DataFrame(X_test) #5
plot_boundary(model, df[0], df[1], y_test, "df [0]", "df [1]")参考資料:Python3年生機械学習のしくみ
実行結果
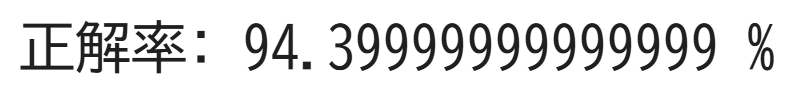
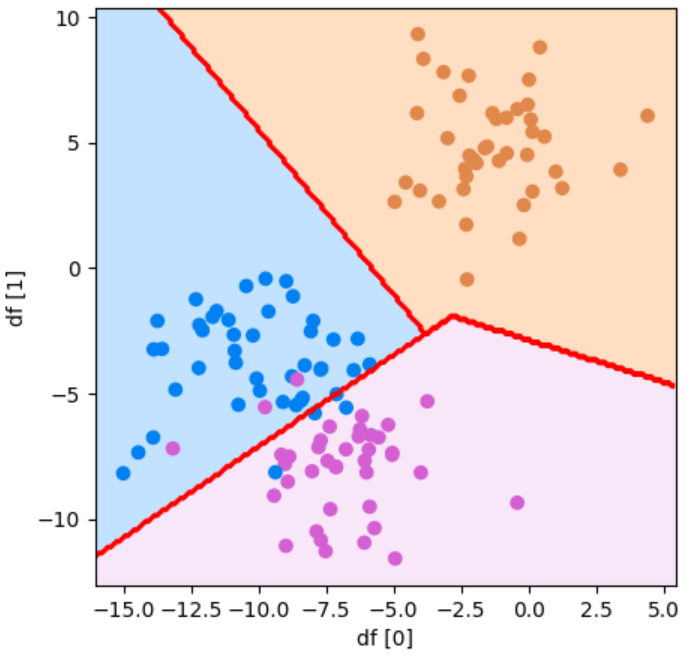
直線で3つに分類することができました!
非線形分類
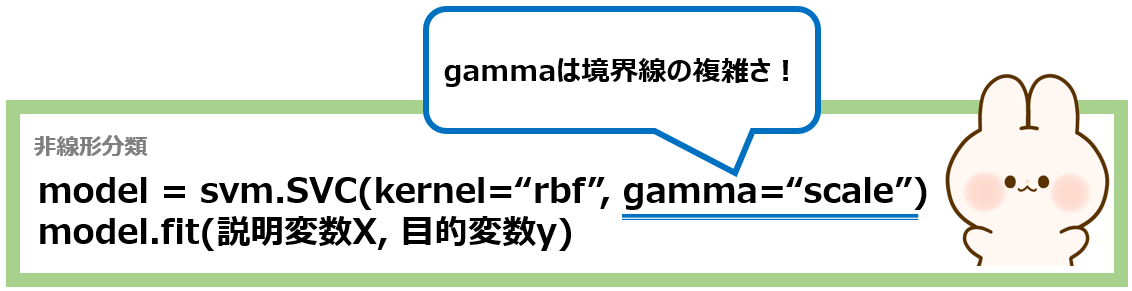
次に、非線形分類を行ってみましょう。先ほど用意したデータを用いて、境界線の複雑さを1に設定して学習を行いましょう!
コード
#1 訓練データを使ってガウスカーネル法のSVMで学習モデルを作成
#2 テストデータを使って正解率を調べる
#3 テストデータを使ってこの学習モデルの分類の様子を表示する
model = svm.SVC(kernel="rbf", gamma=1) #1
model.fit(X_train, y_train)
pred = model.predict(X_test) #2
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")
df = pd.DataFrame(X_test) #3
plot_boundary(model, df[0], df[1], y_test, "df [0]", "df [1]")参考資料:Python3年生機械学習のしくみ
実行結果
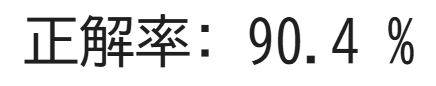
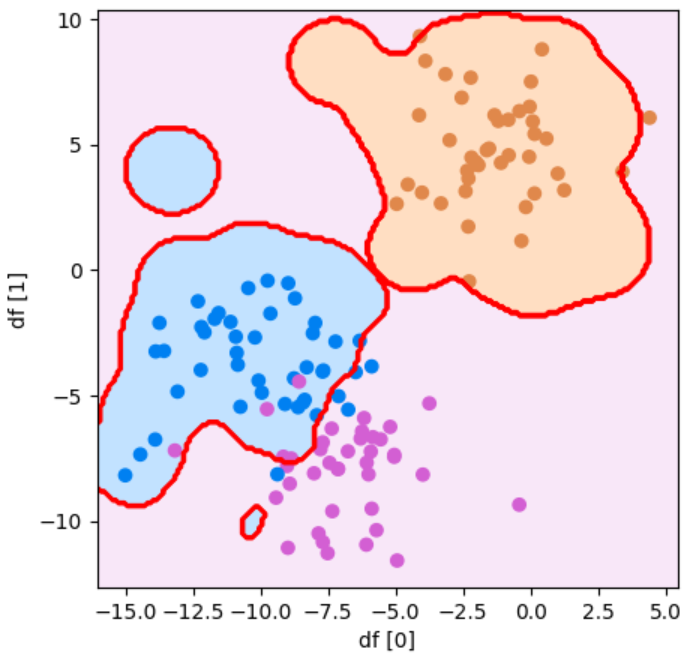
これで非線形な境界線になりました!
このgammaの値は、大きくすると複雑に、小さくすると単純な線に変わります。
次回はgammaの値を変更してみて学習を行ってみましょう!