
機械学習は「線を引く」
機械学習は予測や分類を行うと学びました。
では、どうやって機械学習は予測や分類をしているのでしょうか?
私たちと同じような考え方で予測や分類を行いません。
実は「線を引く」という方法で考えています。
データから見つけた特徴を表現するために線を引きます。
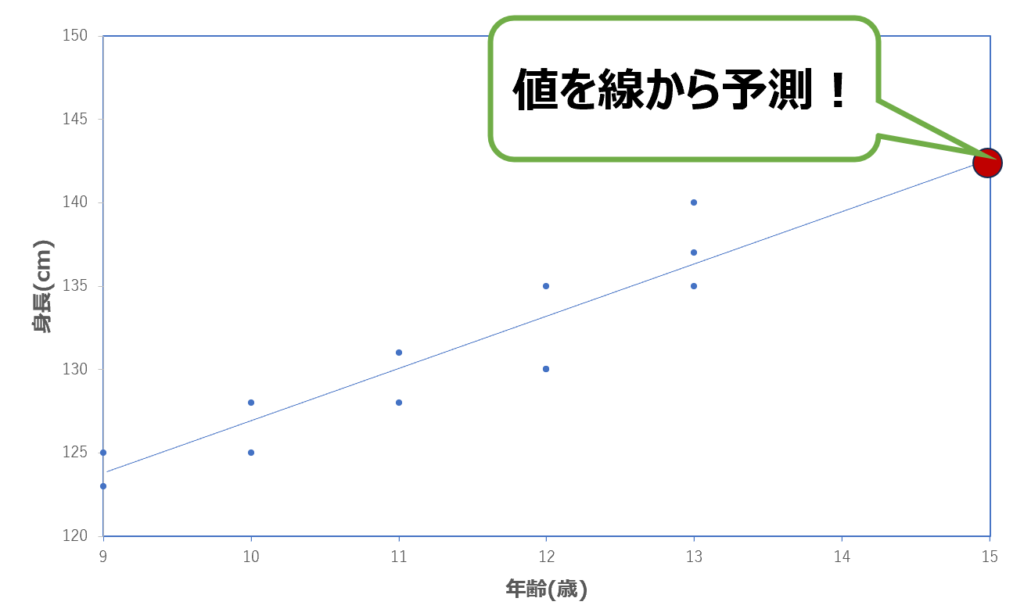
まず、上のグラフは年齢に対する身長のデータの関係を表すグラフです。
グラフにはたくさんの点がプロットされています。
このようなグラフを散布図といいます。
散布図はデータのばらつきを見るためによく使われます。
この散布図にズレが一番少なくなる線を引いたものが回帰であり、新しい値だとどうなるか予測できます。
回帰を利用すると、上のグラフであれば、もし15歳だと身長は何センチになるか予測できます。
「回帰」は予測の線だとイメージしましょう!
うまく線を引くことは大事
うまく線を引けることは機械学習でとても重要です。
コンピュータがうまく線を引けないときは、はっきりわかってない状態です。
学習で見つけた特徴が少ないと、どのような線を引けばいいのか分からず正確な線を引けません。
また、意味のないデータの特徴を使って線を引くと、正確に予測する線は引けません。
ですから線をうまく引くために良い学習を行います!
特徴量とは
まず機械学習は、現実世界にあるものの性質や状況のような特徴をデータにしてコンピュータに取り込みます。
現実世界の性質や状況の測定できるデータのことを「特徴量」といいます!
特徴量は予測にとって重要なもの、意味のないものがあります。
意味のない特徴を学習してもうまく学習できません。意味のある特徴量を使うことが機械学習にとってとても大事です!
意味のある特徴量を使おう!
意味のある特徴量についてもう少し具体的に見てみましょう!
果物の種類を予測するモデルを考えてみます。

果物の特徴量として、色、形、大きさ、重さなどが考えられます。これらの特徴量は果物の種類を予測する意味のある特徴量でしょう。

ですが、果物を入れる箱の模様や販売場所のような特徴量だとどうでしょうか。
箱の模様の色が「ピンク色」であればその果物の種類は「りんごだ!」と、箱の模様の色は果物の種類を決める特徴としない可能性が高いです。
このように果物の種類と直接的な関係がない特徴量はモデルにとって意味のない特徴量といえます。
説明変数と目的変数
最後に説明変数と目的変数という言葉について知りましょう!
- 説明変数
-
意味のある特徴量(予測や分類を行うための情報)のこと。
モデルが学習する時に利用される。
例:果物の種類を予測するモデルの説明変数は色、形、大きさ、重さなど - 目的変数
-
モデルが予測する対象の変数のこと。
モデルの出力(予測結果)となる。
例:果物の種類を予測するモデルの目的変数は果物の種類
機械学習では、与えられた説明変数から目的変数を予測するモデルを学習します!
参考資料:Python3年生機械学習のしくみ
Python2年生データ分析のしくみ