01. Pythonでデータをダウンロード
02. HTMLを解析しよう
03. 表データを読み書きしよう
04. オープンデータを分析してみよう
05. Web APIでデータを収集しよう
参考教科書:Python2年生スクレイピングのしくみ
スクレイピングの詳細
01. Pythonでデータをダウンロード
コード
import requests
# Webページを取得する
url = "https://www.ymori.com/books/python2nen/test1.html"
response = requests.get(url)
# 文字化けしないようにする
response.encoding = response.apparent_encoding
# ファイルを書き込みモードで開いて
filename = "download.txt"
with open(filename, mode="w") as f:
# ネットから取得した読み込んだデータを書き込む
f.write(response.text)結果
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Python2年生</title>
</head>
<body>
<h2>第1章 Pythonでデータをダウンロード</h2>
<ol>
<li>スクレイピングってなに?</li>
<li>Pythonをインストールしてみよう</li>
<li>requestsでアクセスしてみよう</li>
</ol>
</body>
</html>
02. HTMLを解析しよう
コード
import requests
from bs4 import BeautifulSoup
import urllib
# Webページを取得して解析する
load_url = "https://www.ymori.com/books/python2nen/test2.html"
html = requests.get(load_url)
soup = BeautifulSoup(html.content, "html.parser")
# すべてのimgタグを検索し、リンクを取得する
for element in soup.find_all("img"):
src = element.get("src")
# 絶対URLと、ファイルを表示する
image_url = urllib.parse.urljoin(load_url, src)
filename = image_url.split("/")[-1]
print(image_url, ">>", filename)結果

03. 表データを読み書きしよう
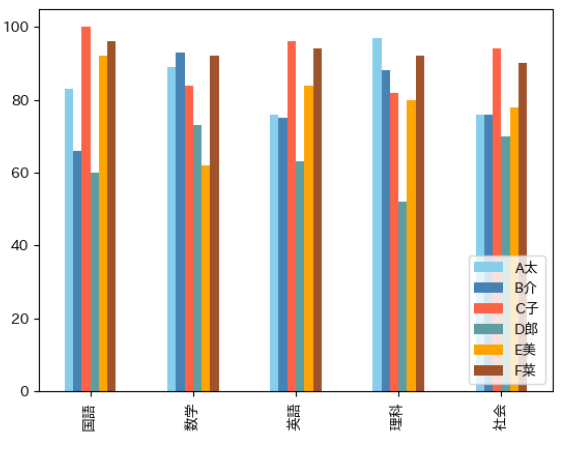
04. オープンデータを分析してみよう
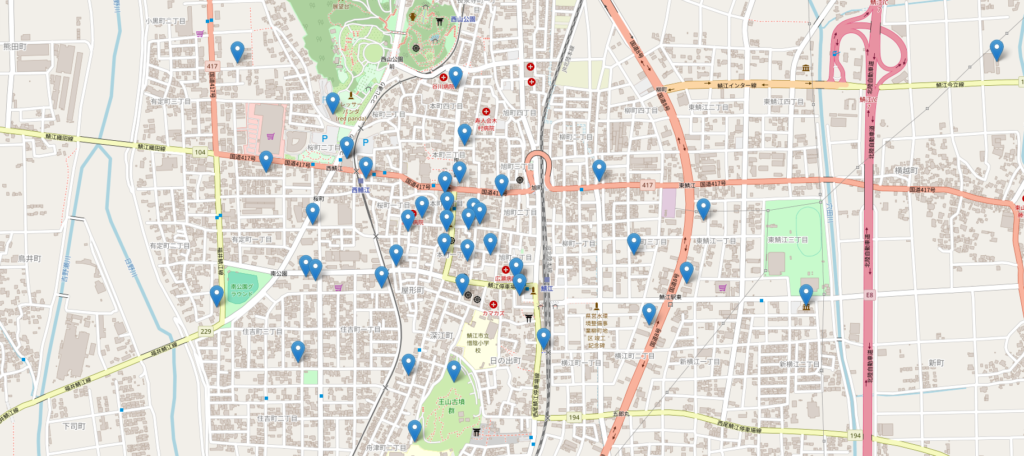
05. Web APIでデータを収集しよう
コード
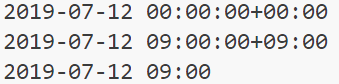
from datetime import datetime, timedelta, timezone
# UTC(協定世界時)をJST(日本標準時)に変換
timestamp = 1562889600
tz = timezone(timedelta(), 'UTC')
utc = datetime.fromtimestamp(timestamp, tz)
print(utc)
tz = timezone(timedelta(hours=+9), 'JST')
jst = datetime.fromtimestamp(timestamp, tz)
print(jst)
print(str(jst)[:-9])結果