
前回まではデータセットの自動生成について学習しました。
今回からは機械学習のしくみを手順を追って学んでいきましょう!
機械学習の中でも最もイメージしやすい「教師あり学習」を学習します。
機械学習とは「機械」の「学習」ですので、私たちの勉強法と同じく、問題をたくさん解いてパターンを学習していき、テストをして理解できているかを確認する。
この繰り返しを行うのです!
STEP
データを用意する
STEP
データを学習用とテスト用に分ける
STEP
モデルを選び学習する
STEP
モデルをテストする
STEP
値を用意して予測する
このステップに従って機械学習を行っていきますが、実際には1~4のステップを繰り返し行うことでより精度の高い予測が可能となります。
今回はステップ1:データを用意するを行いましょう!
目次
ステップ1:データを用意する
まず最初に新規ノートブックを作りましょう。
例として、「2種類に分類する学習」を行ってみましょう。
2種類に分類するために2つの塊を生成するデータセットを用意します!
ランダムの種:0
特徴量:2
塊数:2
ばらつき:1
点の数:500
を指定して2つの塊を生成しましょう。
コード
from sklearn.datasets import make_blobs
import pandas as pd
X, y = make_blobs(
random_state=0,
n_features=2,
centers=2, #塊数2
cluster_std=1,
n_samples=500) #点の数500
# 特徴量Xでデータフレームを作り、分類yをtargetの列とする
df = pd.DataFrame(X)
df["target"] = y
df.head()
参考資料:Python3年生機械学習のしくみ
実行結果
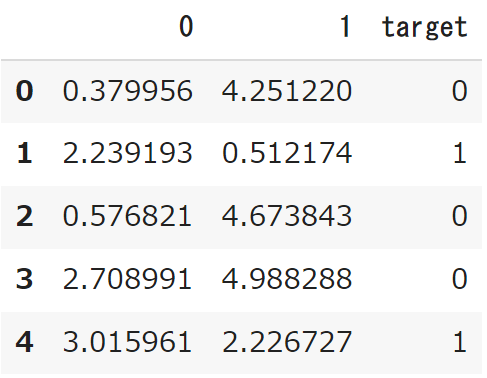
targetが各データの分類です。
では、データの様子を散布図で確認してみます。
コード
#1~2 分類別にデータフレームに分ける
#3~4 シアンとマゼンタの散布図
import matplotlib.pyplot as plt
%matplotlib inline
# 分類によって、別々のデータフレームに分ける
df0 = df[df["target"]==0] #1
df1 = df[df["target"]==1] #2
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.4) #3
plt.scatter(df1[0], df1[1], color="m", alpha=0.4) #4
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
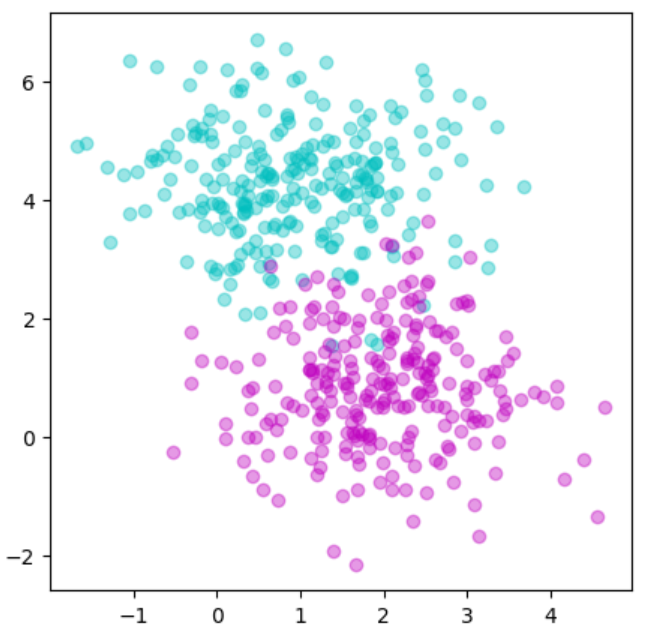
真ん中が少し混ざっていますがこの部分が問題にどのように影響するのか注目しておきましょう!