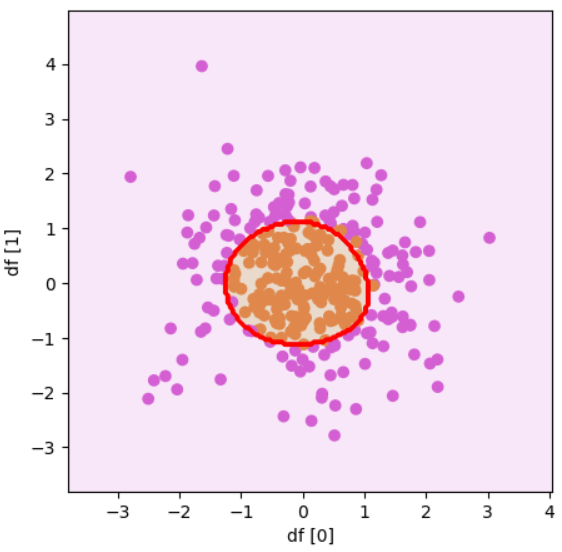
前回に引き続き作成した関数を使って、今回は直線で分割することが出来ないデータセットを用いて実際に散布図を確認していきましょう!
目次
三日月型のデータセット
以前学んだmake_moons命令を用いて三日月型のデータセットを作成して関数に与えてみましょう!
コード
#1 ランダムの種:1、ノイズ:0.1、点の数:300個の三日月型のデータセット
#2 特徴量データ(X)で、データフレームを作成
#3 モデルを作って学習
#4 分類の状態を表示
from sklearn.datasets import make_moons
X, y = make_moons(random_state=1, #1
noise=0.1,
n_samples=300)
df = pd.DataFrame(X) #2
model = svm.SVC() #3
model.fit(X, y)
plot_boundary(model, df[0], df[1], y, "df [0]", "df [1]") #4参考資料:Python3年生機械学習のしくみ
実行結果
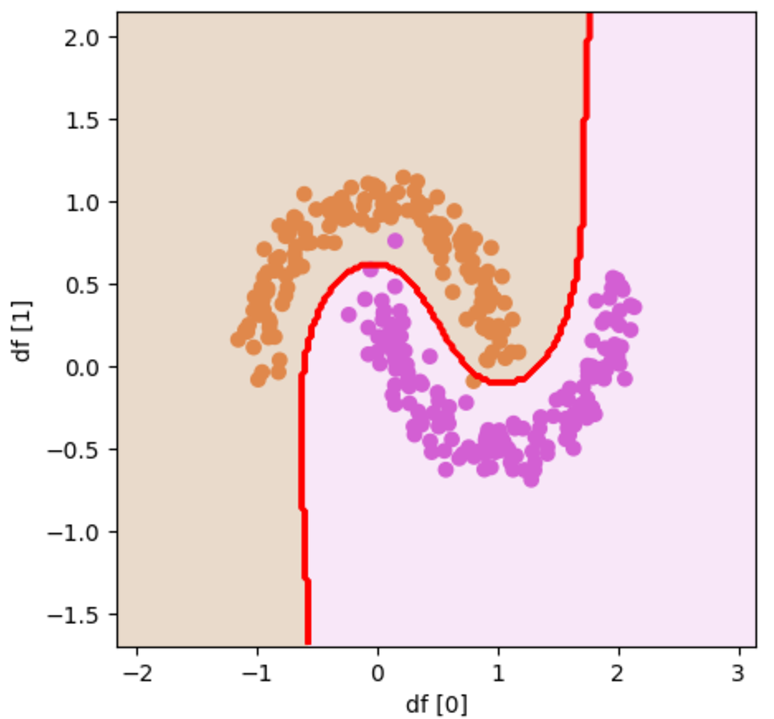
直線で分割することが出来ない形のデータセットでも境界線が曲がって、しっかりと分けることが出来ています!
二重円型のデータセット
もうひとつ試してみましょう!以前学んだmake_circles命令を用いて二重円型のデータセットを作成して関数に与えてみましょう!
コード
#1 ランダムの種:1、ノイズ:0.1、点の数:300個の二重円型のデータセット
#2 特徴量データ(X)で、データフレームを作成
#3 モデルを作って学習
#4 分類の状態を表示
from sklearn.datasets import make_circles
X, y = make_circles(random_state=1, #1
noise = 0.1,
n_samples=300)
df = pd.DataFrame(X) #2
model = svm.SVC() #3
model.fit(X, y)
plot_boundary(model, df[0], df[1], y, "df [0]", "df [1]") #4参考資料:Python3年生機械学習のしくみ
実行結果
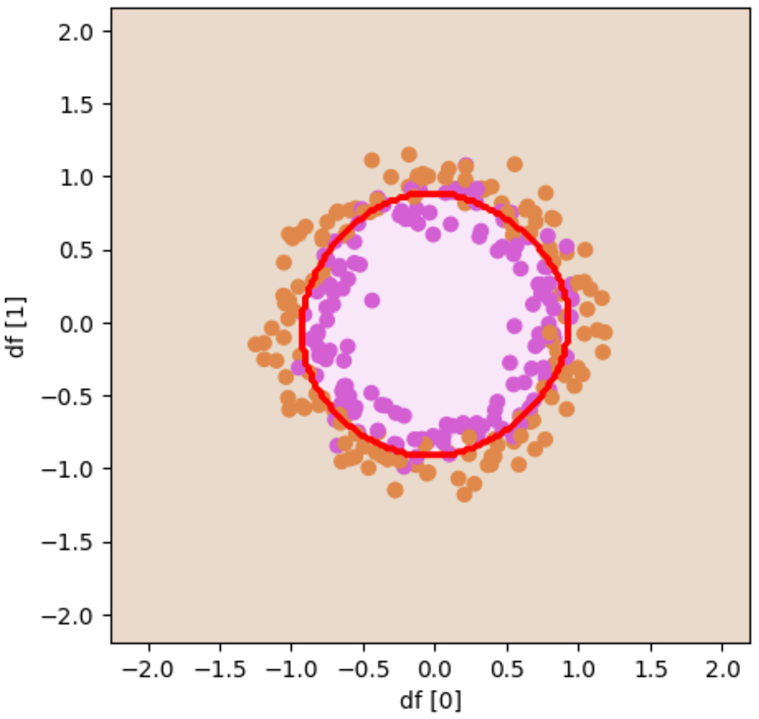
円の形でも、外側と内側でしっかりと区切られていることが確認できました!
確認問題
ランダムの種=1
特徴量=2
グループ=2
点の数=300
の同心円のデータセットを作成して、関数を使い分類の状態を表示しましょう。
答えはコチラをクリック!
答え:
#1 ランダムの種:1、特徴量:2、グループ:2、点の数:300個の同心円型のデータセット
#2 特徴量データ(X)で、データフレームを作成
#3 モデルを作って学習
#4 分類の状態を表示
import pandas as pd
from sklearn import svm
from sklearn.datasets import make_gaussian_quantiles
X, y = make_gaussian_quantiles(
random_state=1,
n_features=2,
n_classes=2,
n_samples=300)
df = pd.DataFrame(X) #2
model = svm.SVC() #3
model.fit(X, y)
plot_boundary(model, df[0], df[1], y, "df [0]", "df [1]") #4