
前回に引き続き塊のデータを生成する方法について学びましょう!
目次
②塊の数が3つのデータを作ろう
前回と同じ条件
ランダムの種 = 4
特徴量 = 2
塊の数 = 2
ばらつき = 1
点の数 = 300
を使って塊の数=3に変更し、データセットを作りましょう!
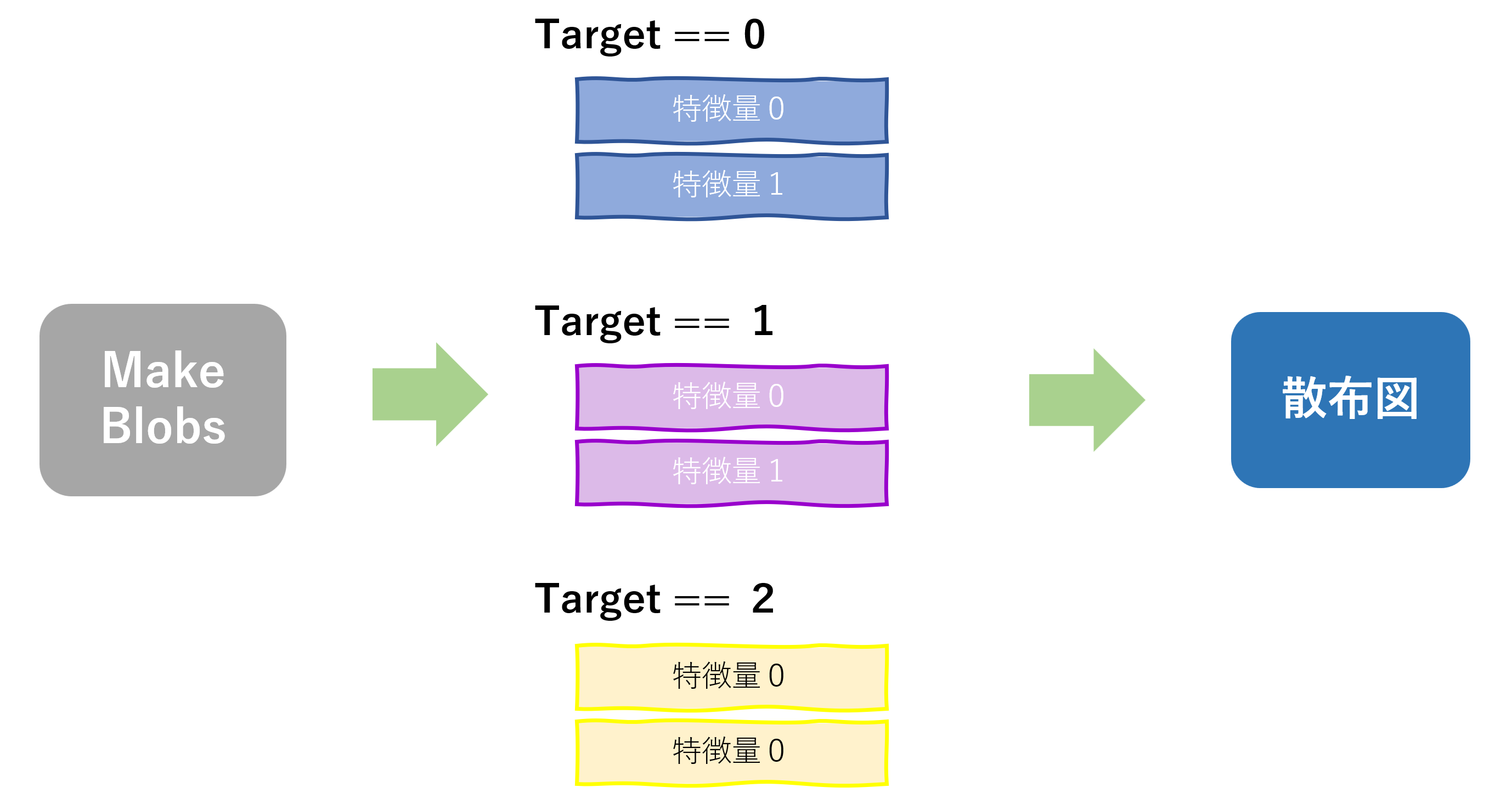
コード
X, y = make_blobs(
random_state=4,
n_features=2,
centers=3, #1
cluster_std=1,
n_samples=300)
df = pd.DataFrame(X)
df["target"] = y
df0 = df[df["target"]==0] #2
df1 = df[df["target"]==1] #3
df2 = df[df["target"]==2] #4
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.4)
plt.scatter(df1[0], df1[1], color="m", alpha=0.4)
plt.scatter(df2[0], df2[1], color="y", alpha=0.4) #5
plt.grid()
plt.show()
#1 塊の数:3つ
#2~4 分類別にデータフレームを分ける
#5 黄色の散布図参考資料:Python3年生機械学習のしくみ
実行結果
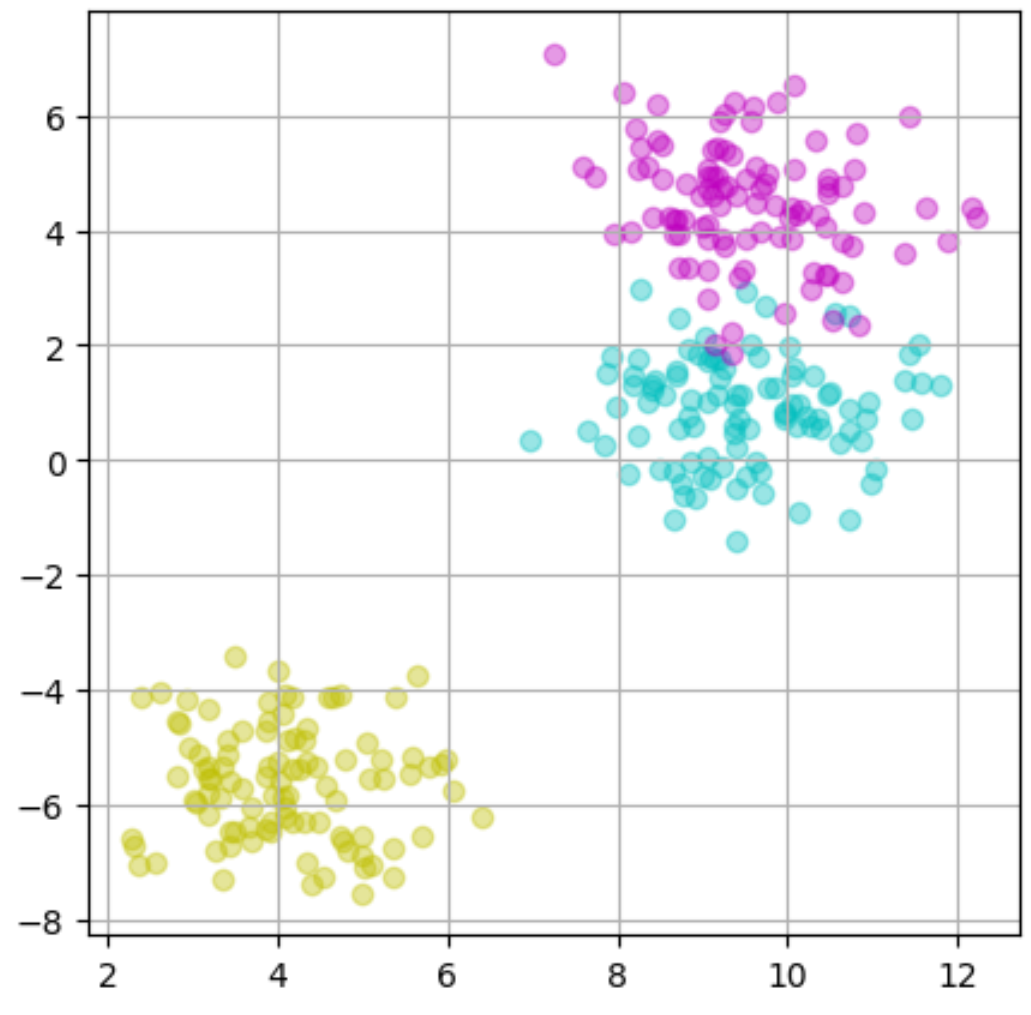
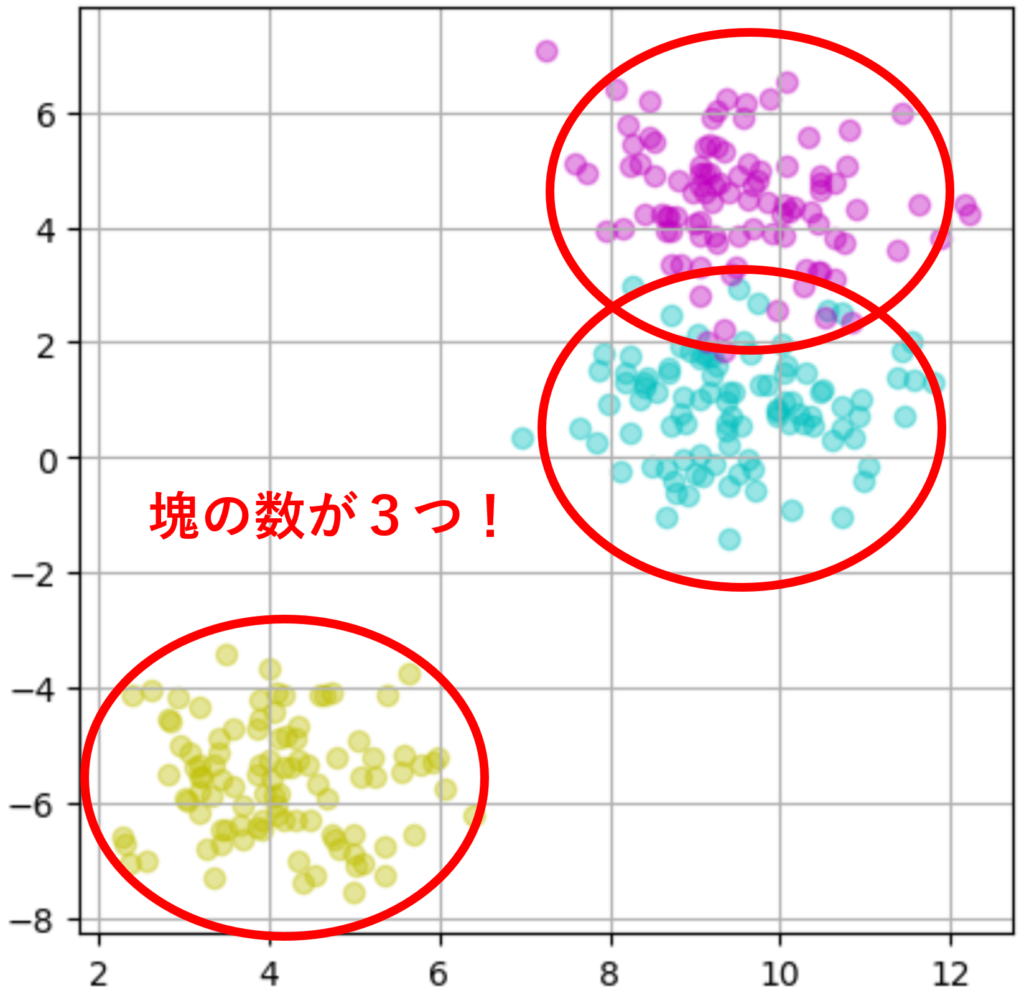
これで塊の数が3つのデータを生成することが出来ました!
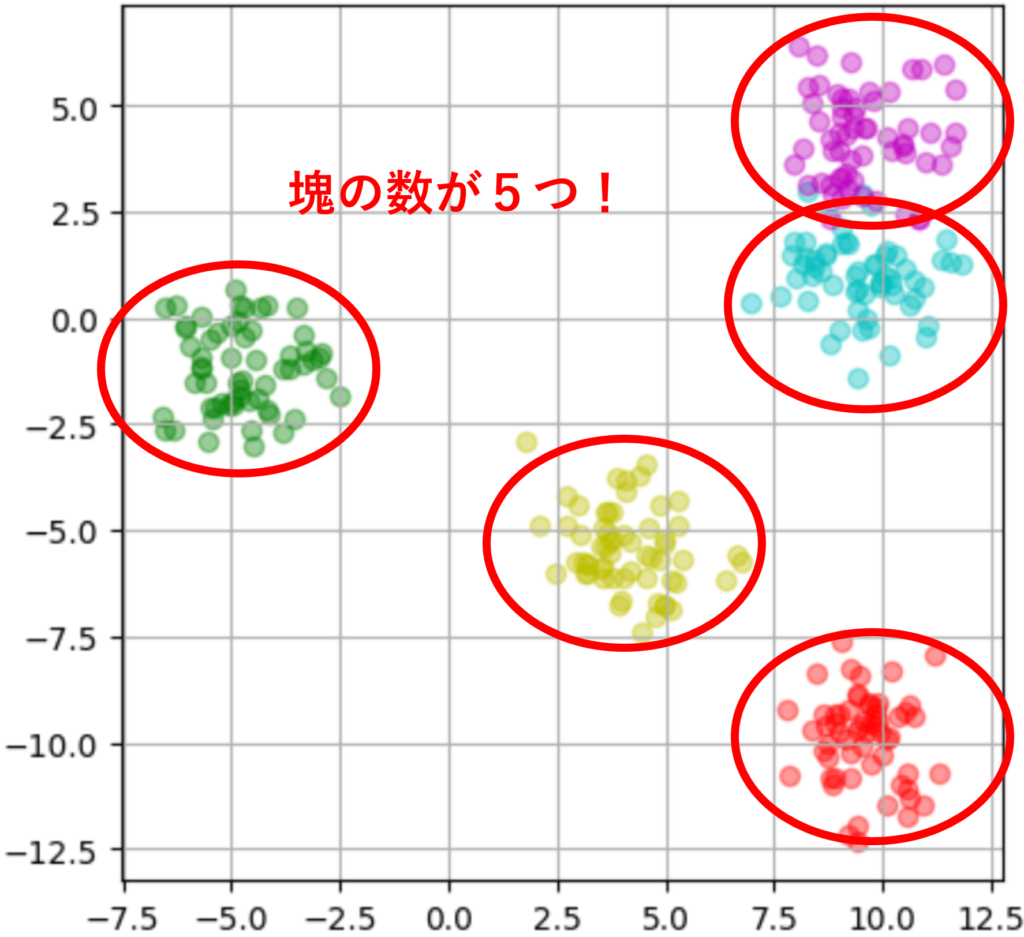
③塊の数が5つのデータを作ろう
また同じ条件で、塊の数=5に変更し、データセットを作りましょう!
もう変更方法が理解できた方は次のサンプルコードを見ずに作成してみましょう!
コード
X, y = make_blobs(
random_state=4,
n_features=2,
centers=5, #1
cluster_std=1,
n_samples=300)
df = pd.DataFrame(X)
df["target"] = y
df0 = df[df["target"]==0] #2
df1 = df[df["target"]==1] #3
df2 = df[df["target"]==2] #4
df3 = df[df["target"]==3] #5
df4 = df[df["target"]==4] #6
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="c", alpha=0.4)
plt.scatter(df1[0], df1[1], color="m", alpha=0.4)
plt.scatter(df2[0], df2[1], color="y", alpha=0.4)
plt.scatter(df3[0], df3[1], color="r", alpha=0.4) #7
plt.scatter(df4[0], df4[1], color="g", alpha=0.4) #8
plt.grid()
plt.show()
#1 塊の数:5つ
#2~6 分類別にデータフレームを分ける
#7 赤色の散布図
#8 緑色の散布図参考資料:Python3年生機械学習のしくみ
実行結果
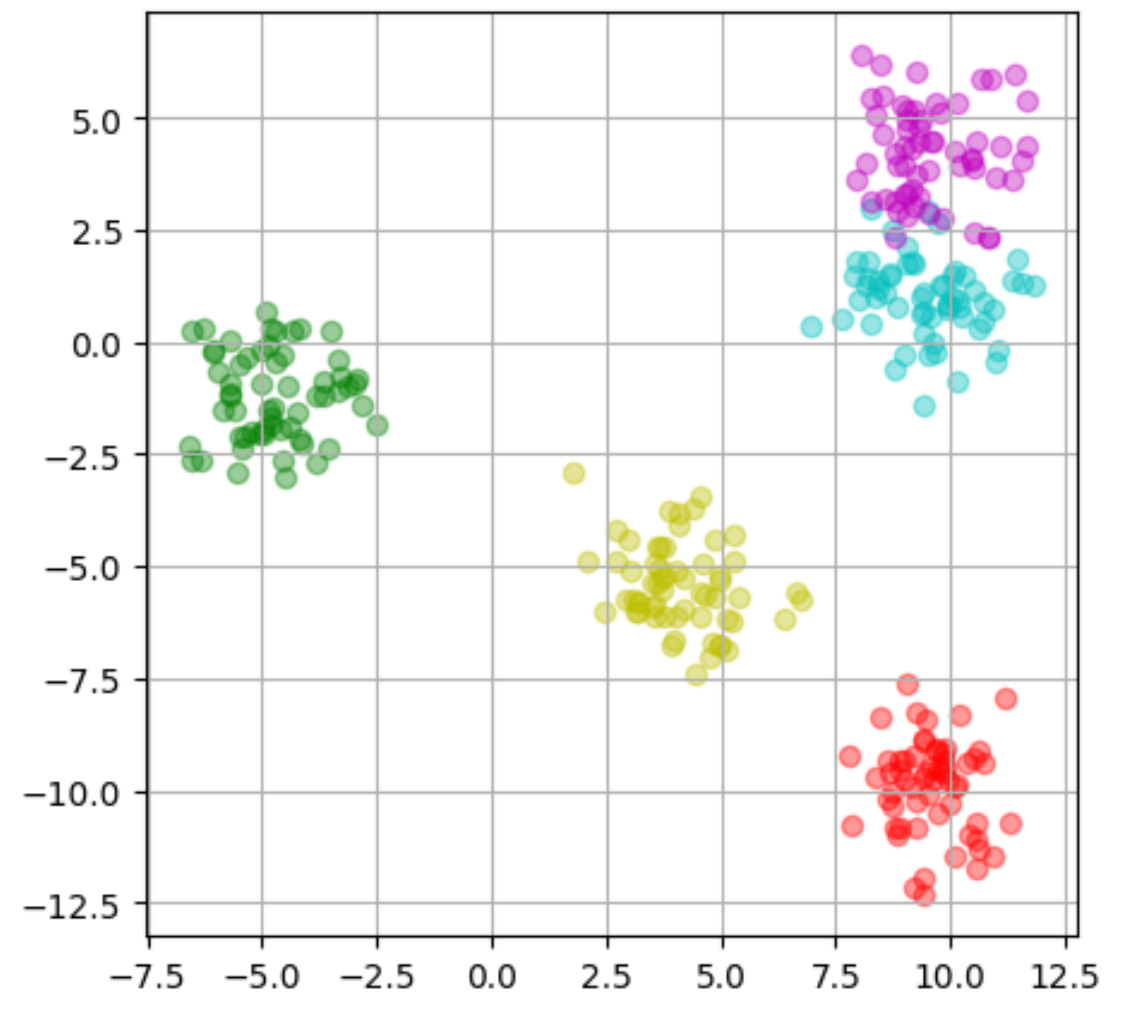
確認問題
ランダムの種=3
特徴量=2
塊数=3
ばらつき=0.8
点の数=300
の塊のデータセットを作成して、青と赤と緑の散布図を半透明で描画してみましょう。
答えはコチラをクリック!
答え:
from sklearn.datasets import make_blobs
import pandas as pd
X, y = make_blobs(
random_state=3,
n_features=2,
centers=3,
cluster_std=0.8,
n_samples=300)
df = pd.DataFrame(X)
df["target"] = y
df0 = df[df["target"]==0]
df1 = df[df["target"]==1]
df2 = df[df["target"]==2]
plt.figure(figsize=(5, 5))
plt.scatter(df0[0], df0[1], color="b", alpha=0.5)
plt.scatter(df1[0], df1[1], color="r", alpha=0.5)
plt.scatter(df2[0], df2[1], color="g", alpha=0.5)
plt.grid()
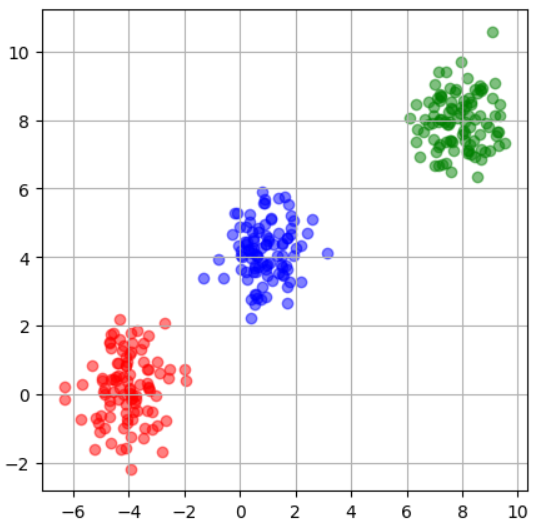
plt.show()ヒント
このような散布図になるはずです!
これで塊の数が増えてもデータセットを作成できることが分かったと思います!
次回は三日月型のデータセットについて学んでいきましょう!