目次
深度を指定して学習
前回使ったデータをそのまま使用して分岐の深度を最大2にしたモデルを使って学習してみましょう!
コード
#1 分岐の深度を最大2にすして、訓練データで決定木の学習モデルを作成
#2 テストデータで正解率を調べる
#3 テストデータでこの学習モデルの分類の状態を表示
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=2, random_state=0)
model.fit(X_train, y_train)
pred = model.predict(X_test)
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")
df = pd.DataFrame(X_test)
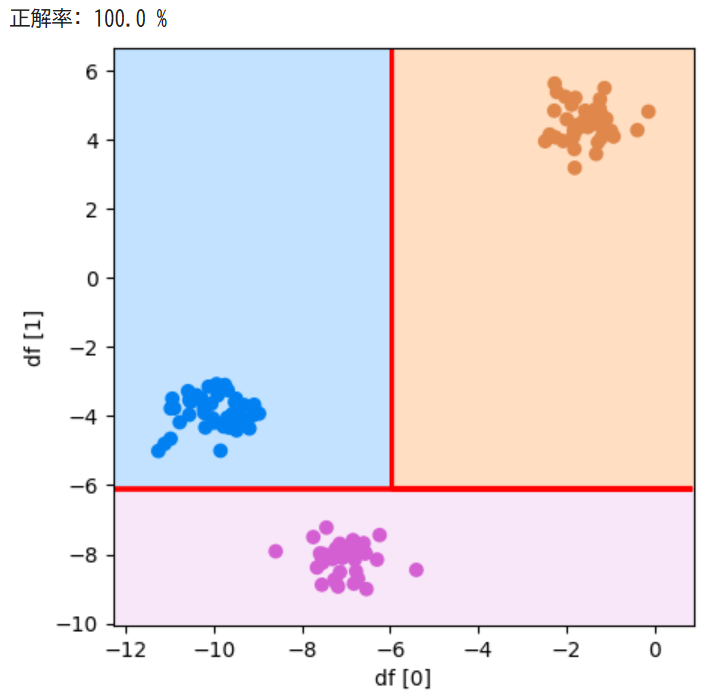
plot_boundary(model, df[0], df[1], y_test, "df [0]", "df [1]")参考資料:Python3年生機械学習のしくみ
実行結果
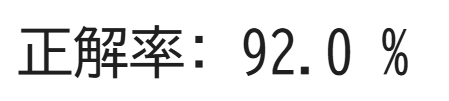
先ほどの結果と比べるととてもシンプルな分類になりました!そして、正解率も下がっているようです。
ツリー構造も確認してみましょう!
コード
from sklearn.tree import plot_tree
plt.figure(figsize=(15, 15))
plot_tree(model, fontsize=20, filled=True,
feature_names=["df [0]", "df [1]"],
class_names=["0","1","2"])
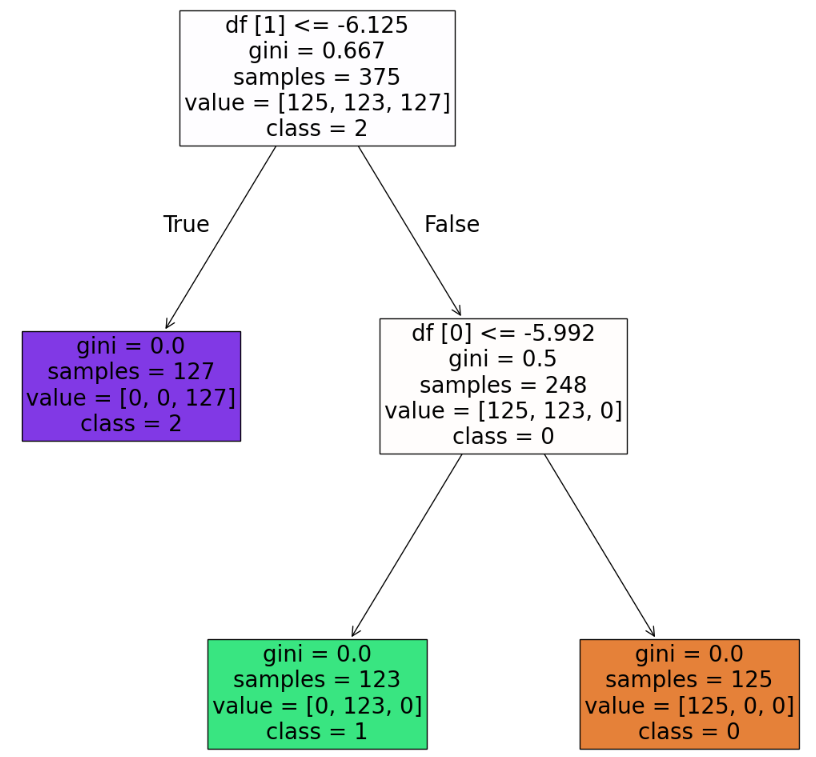
plt.show()参考資料:Python3年生機械学習のしくみ
実行結果
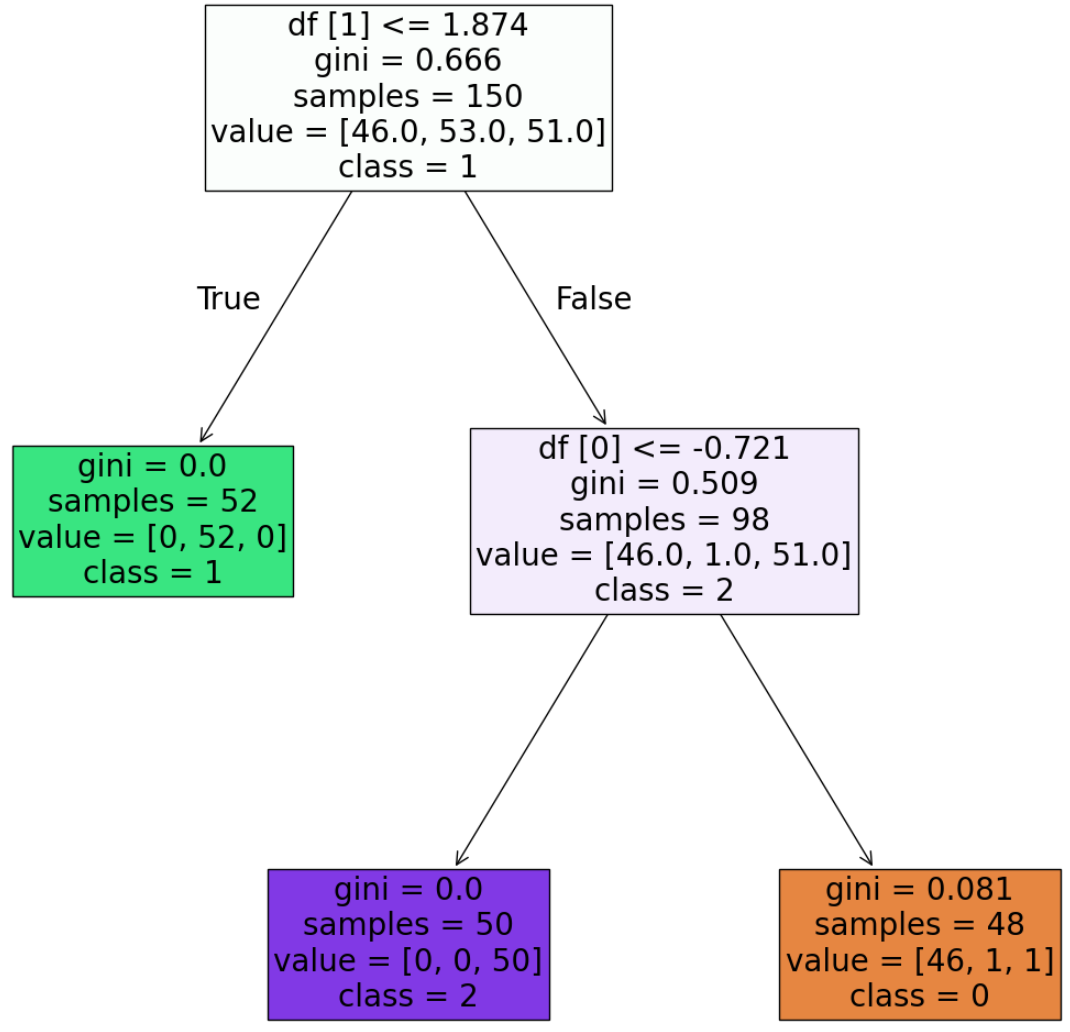
分岐も二つに減っていますね。
このツリー構造とグラフも見比べてみましょう!
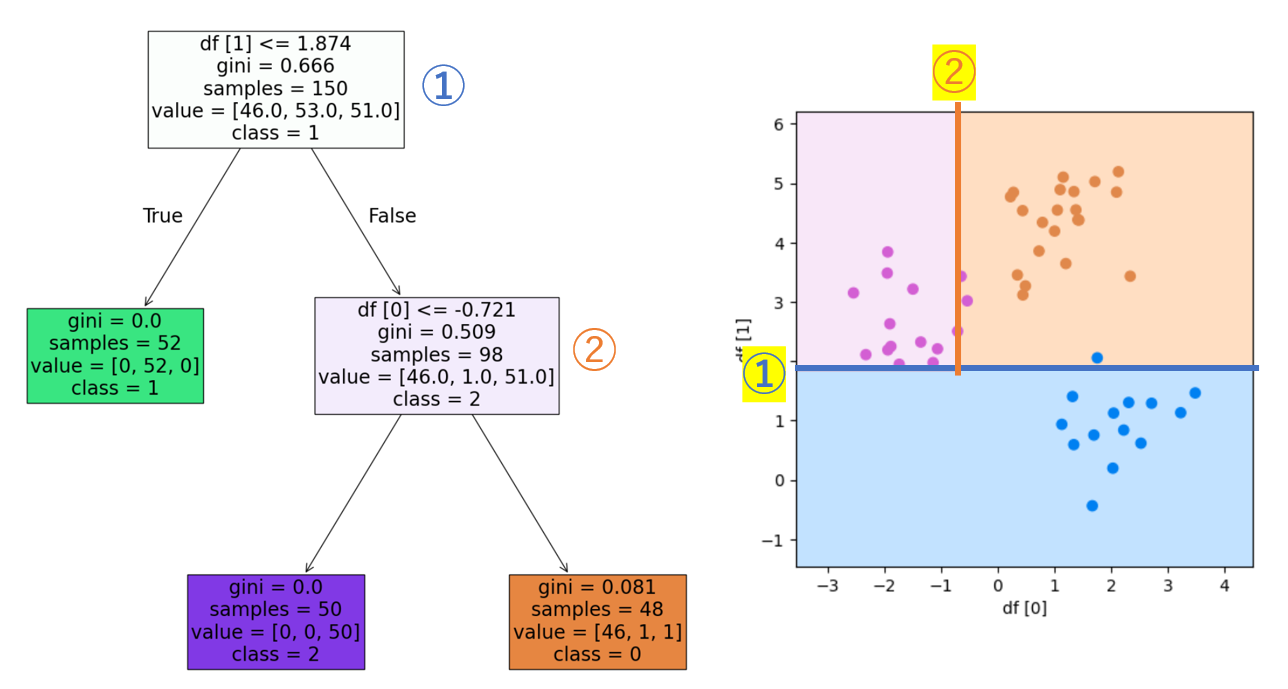
深さが減ったことでとてもシンプルな分類になったことがわかります。このように、深度を調整して良い精度になるようにバランスをよくすることが重要です!
確認問題
ランダムの種:1
特徴量:2
グループ:3
ばらつき:0.5
点の数:500個
の塊型のデータセットをつかって決定木の分類を散布図で表示して、ツリー構造も表示してみましょう。このとき、深度の最大は設定しないで表示してみます。
答えはコチラをクリック!
答え:
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
X, y = make_blobs(
random_state=1,
n_features=2,
centers=3,
cluster_std=0.5,
n_samples=500)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = DecisionTreeClassifier(max_depth=None, random_state=0)
model.fit(X_train, y_train)
pred = model.predict(X_test)
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")
df = pd.DataFrame(X_test)
plot_boundary(model, df[0], df[1], y_test, "df [0]", "df [1]")
plt.figure(figsize=(15, 15))
plot_tree(model, fontsize=20, filled=True,
feature_names=["df [0]", "df [1]"],
class_names=["0","1","2"])
plt.show()ヒント
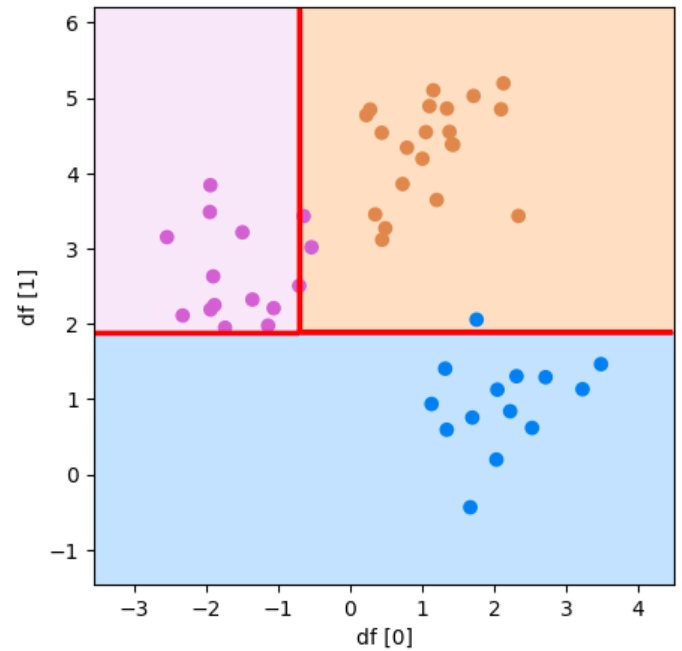
このような散布図になるはずです!