目次
ランダムフォレストとは?
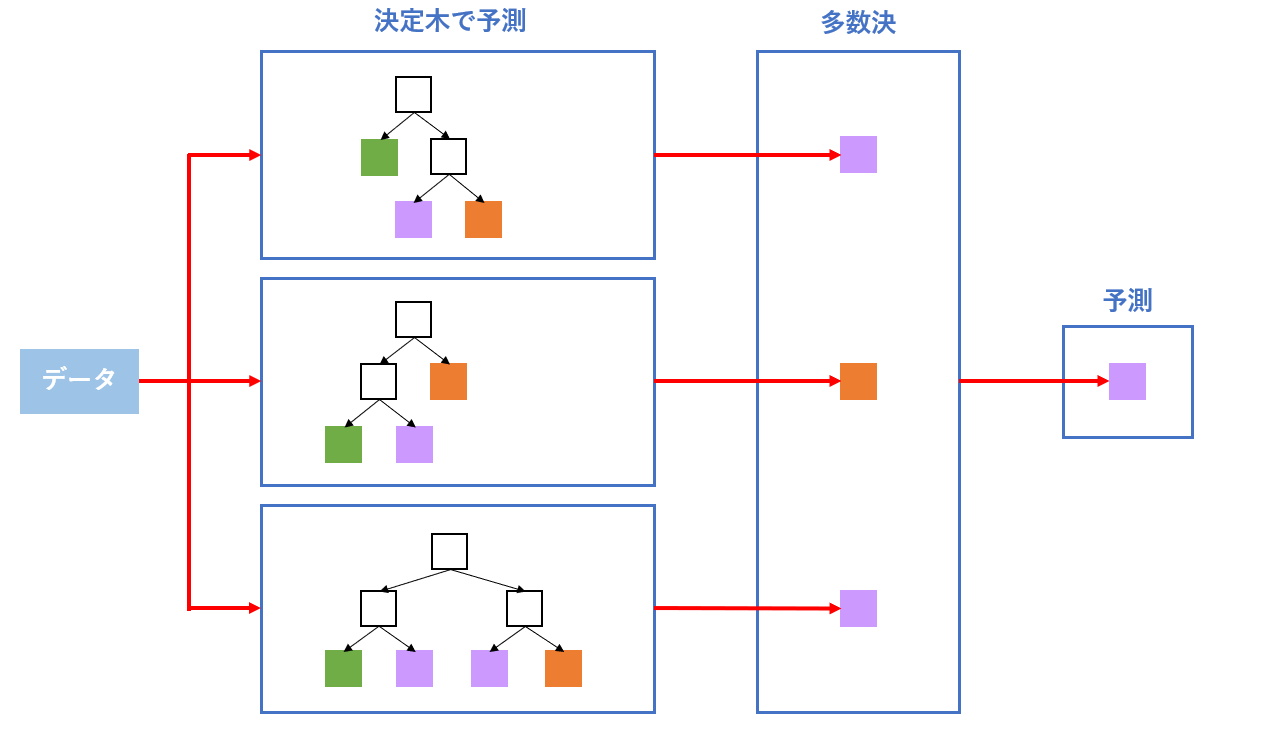
ランダムフォレストとは決定木の予測精度をより上げるために考えられた分類方法です。
簡単に説明すると、決定木をたくさん作って多数決で予測する制度の高いアルゴリズムということです!
ランダムフォレストの使い方

上記の書式を用いて学習させたモデルにpredict命令で説明変数Xを渡すと予測結果が帰ってきます。
ランダムフォレストを試してみる
決定木と同じデータである
ランダムの種:0
特徴量:2
塊数:3
ばらつき:0.6
点の数:500
のデータセットを用いてランダムフォレストの分類を散布図で確認してみましょう!
コード
#1 ランダムの種:0、特徴量:2、塊数:3、ばらつき:0.6、点の数:500個のデータセットを作成
#2 訓練データを使ってランダムフォレストの学習モデルを作成
#3 テストデータを使っって正解率を調べる
#4 テストデータを使ってこの学習モデルの分類の状態を表示
from sklearn.ensemble import RandomForestClassifier
X, y = make_blobs(
random_state=0,
n_features=2,
centers=3,
cluster_std=0.6,
n_samples=200)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = RandomForestClassifier()
model.fit(X_train, y_train)
pred = model.predict(X_test)
score = accuracy_score(y_test, pred)
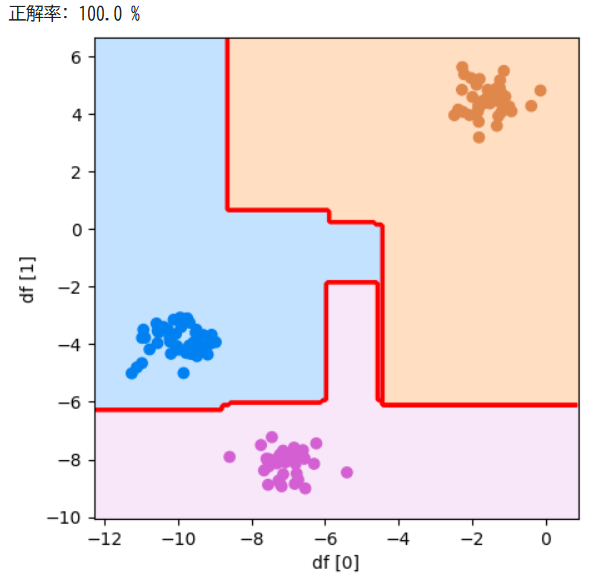
print("正解率:", score*100, "%")
df = pd.DataFrame(X_test)
plot_boundary(model, df[0], df[1], y_test, "df [0]", "df [1]")参考資料:Python3年生機械学習のしくみ
実行結果

決定木と比較すると正解率が上がりました!分類している線も決定木より複雑になっていることがわかります!
確認問題
ランダムの種:1
特徴量:2
グループ:3
ばらつき:0.5
点の数:500個
の塊型のデータセットをつかってランダムフォレストの分類を散布図で表示してみましょう。
答えはコチラをクリック!
答え:
from sklearn.ensemble import RandomForestClassifier
X, y = make_blobs(
random_state=1,
n_features=2,
centers=3,
cluster_std=0.5,
n_samples=500)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model = RandomForestClassifier()
model.fit(X_train, y_train)
pred = model.predict(X_test)
score = accuracy_score(y_test, pred)
print("正解率:", score*100, "%")
df = pd.DataFrame(X_test)
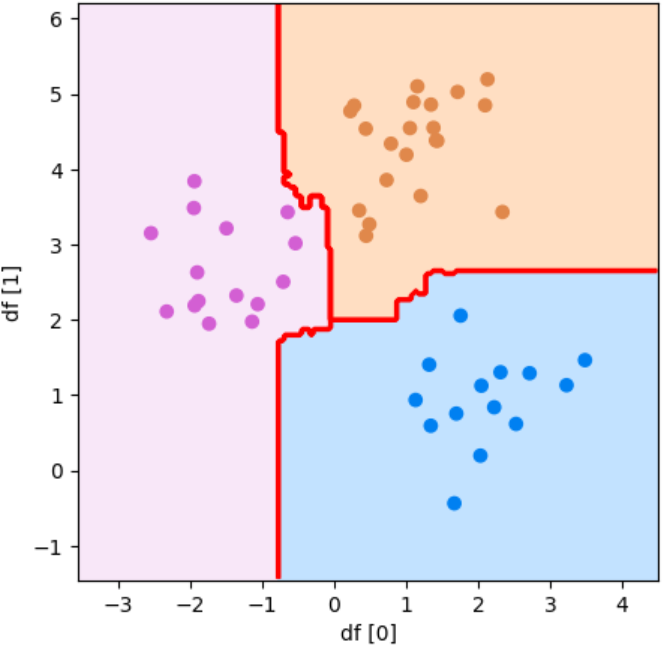
plot_boundary(model, df[0], df[1], y_test, "df [0]", "df [1]")ヒント
このような散布図になるはずです!